Is there any role for the Taylor rule in helping predict exchange rates?
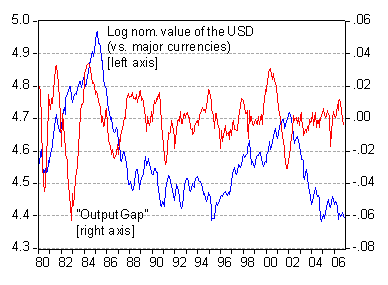
Figure 1: Log nominal value of the dollar (vs. major currencies, Federal Reserve measure), and deviation of industrial production from HP filtered series (over 1967-2006 period). Source: FRED II and author’s calculations.
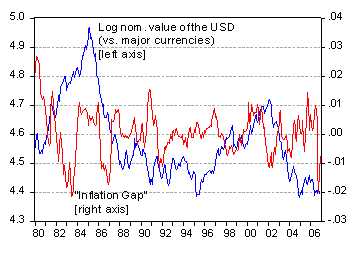
Figure 2: Log nominal value of the dollar (vs. major currencies, Federal Reserve measure), and deviation of CPI inflation rate (12 month difference of logged series) from HP filtered series (over 1967-2006 period). Source: FRED II and author’s calculations.
My colleagues Charles Engel and Kenneth West at the University of Wisconsin have written a paper [pdf] suggesting that the presence of Taylor rules (the tendency for central banks to adjust overnight interbank interest rates in response to deviations from targetted GDP and inflation) might explain part of the movements of the DM/dollar rate, but not more than 40% of the variation. In my view, this is an important result, especially against the backdrop of generally dismal results in the exchange rate prediction business.
More recently, Tanya Molodtsova and David Papell at the University of Houston have analyzed the out of sample forecasting performance of models based upon Taylor rule fundamentals, namely relative output gaps and inflation rates (they also assess a Taylor rule specification augmented with the real exchange rate) [pdf]. Since they are using monthly data, the output gaps are calculated using linear and quadratic detrending of industrial production, as well as HP filtered industrial production. They conclude:
‘Research on exchange rate predictability has come full circle from the “no predictability at short horizons” results of Meese and Rogoff (1983a, b) to the “predictability at long horizons but not short horizons” results of Mark (1995) and Chen and Mark (1996) to the “no predictability at any horizons” results of Cheung, Chinn, and Pascual (2005). We come to a very different conclusion, reporting strong evidence of exchange rate predictability at the one-month horizon, slight evidence of predictability at the three-month horizon, and no evidence of predictability at longer horizons.’
In addition they find that the short horizon outperformance is most pronounced for the Taylor model at the short horizon. In their inferences, it turns out to be important to use the Clark-West statistic, which yields properly sized tests in this case, as opposed to the Diebold-Mariano statistic. (For a discussion of the forecasting power of other fundamentals, also using the Clark-West test statistic, see this paper,).
Technorati Tags: dollar,
exchange rates,
output gap,
inflation gap,
Taylor rule,
forecast, and
exchange rate modeling
Menzie,
Would you apply the Taylor rule to multiple currencies and CBs in your analysis, or only the the US?
How are the following terms defined in the Taylor rule?
actual inflation (CPI,PPI, other?)
economic activity (GDP?)
“full employment” level (Household survey, other, what is “full employment?”)
the level of the short-term interest rate…consistent with full employment.
DickF: The graphs I provided were merely for illustrative purposes. In the Molodotsva-Papell analysis, bilateral exchange rates were modeled using inter-country differences in output and inflation gaps. The output gap is modeled using the deviation of industrial production (a proxy for real GDP) from a smooth trend. By Okun’s law, unemployment gaps are related to output gaps (so full employment theoretical should be associated out output equaling potential GDP). Inflation gaps are proxied by deviations of (CPI) inflation from a smooth trend.
Different variations of the empirical Taylor rule model will use different proxies for target inflation and target output. However, the proxies mentioned above are representative.