A sequel to my rebuttal to an anti-log manifesto:
Reader Ed Hanson:, commenting on my use of correlation coefficients in analyzing economic policy uncertainty comovements.
My lessen 1 is the danger to statisticians who try to create more precision from the dat than actually exist. Just because you can calculate a number does not mean that number has precision. In other words, Menzie, you are attempting to get more precision out of the Index than actually exist. My visual and general note of spikes of uncertainty has more meaning and correlation than your over mathematical treatment which feigns accuracy.
It is an easy refuge for people to criticize statistical analysis as “lies, damn lies, and statistics”. However, in doing statistical analysis on economic policy uncertainty indices, I think it is useful to distinguish between the data series themselves, and moments of the series data sample (text edited 6:33PM).
First, the EPU is compiled (roughly speaking) using occurrences of the words of “economic”, “policy” and “uncertainty” from newspapers, normalized by total words. One can take issue with the creation of these indices, in terms of there coverage, in terms of normalization, whether the numerical tabulation is representative of actual economic policy uncertainty (I leave it to Baker, Bloom and Davis (2016) to make the case). It’s the use of correlation coefficients to summarize comovement that exercises Mr. Hanson.
So, second, let’s look at the idea of measuring comovement. The Pearson correlation coefficient I cited is estimated as:
ρxy = Cov(x,y)/(Var(x)×Var(y))0.5
Now, a correlation coefficient can always be calculated. There is a deep question of whether there is a population correlation that the estimated correlation coefficient converges to. Of course, that question relates to other parameters one might want to estimate. If for instance x and y are I(1) series, and not cointegrated, then a regression coefficient will not converge to a population parameter because it doesn’t exist.
Still, as a summary of how two observed series comove, the correlation coefficient is useful.
Is my reporting of a correlation coefficient misleadingly precise? Yes, if the underlying indices are reported to three significant digits, and I had reported the correlation coefficient up to 10 significant digits. As it turns out, the US baseline EPU is reported to 16 significant digits, I listed correlations to up to three significant digits.
Now, I could be faulted for not reporting statistical significance, with respect to some interesting null, like ρ=0. Below I show a correlation table with t-stats, for EPU’s over the 2016M01-2018M03.
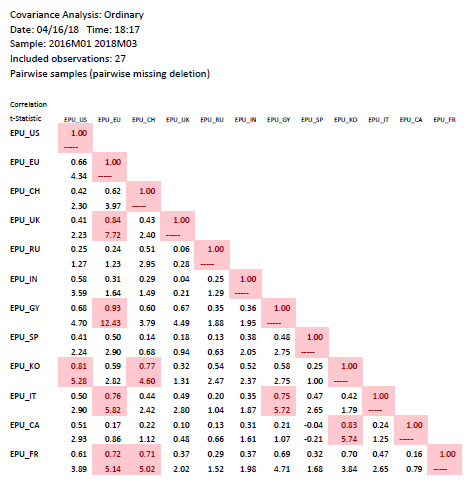
Notice every case where the ρ exceeds 0.707 (consistent with R2 in bivariate context of 0.5), the t-statistic exceeds (in absolute value) 2, signifying statistical significance at the 95% level.
The data are plotted below.
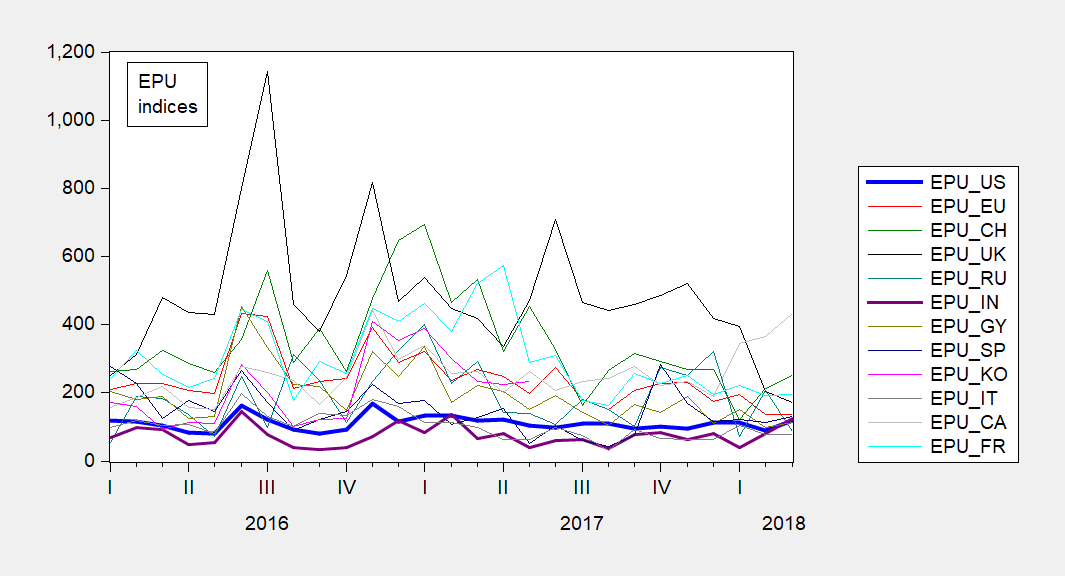
Figure 1: Monthly EPU indices. Source: policyuncertainty.com.
Are there problems with correlation coefficients as summary measures of comovement? Sure. If there are multiple regimes, then a simple correlation coefficient (or a single regression coefficient) might lead to misleading results when a full-sample estimate is applied to a subsample where one regime dominates.
For instance, if there is a high correlation regime and a low correlation regime, then one should use a regime switching procedure (e.g., a Markov-switching procedure). Of course, once again, one would be estimating coefficients which might yield the feeling of precision … to those who are unaware of the uses of statistical analysis. But this is more likely the right way to proceed if one has the feeling that looking at “spikes” is the way to go.
Another, perhaps more relevant, case is when the variances vary over time (i.e., there is heteroskedasticity), but the underlying regression coefficient relating y to x is constant. As Forbes and Rigobon (2002) point out, in such instances, increases in variances will manifest in increases in correlations. So maybe regression coefficients were the way to go. Unfortunately, regression coefficients are not invariant to which variable is placed on the left or right hand side…. so one has to sort through a large number of results (and make a different judgement on what is a large comovement).
In any case, the use of correlation coefficients, in the hands of an informed analyst, seems to me a helpful way to summarize the comovement of variables, and does not necessarily lead to an over-estimate of precision in and of itself.
Now, I’ll go back to defending the use of logn(.), aka ln(.).
Menzie, up in one of your first paragraphs I think you mean movement not moment.
Excellent lesson in econometric by the way.
https://www.youtube.com/watch?v=r5X8qDDMC-o
Not Trampis: I rephrased, so it’s clear I’m talking about moments (e.g., mean, covariance, variance…).
Menzie
Is the black line that peaks above 1100 at Brexit the EPU-UK? Assuming it is, then:
What makes the EPU so different from the front page at policyuncertainty.com?
There it peaks at approximately half the value – 558.
And no Menzie, I am not accusing of cooking the books.
Ed
Quiet Tilford:
https://www.youtube.com/watch?v=hO1HI_3U5HI
Ed Hanson: Beats me. When you download the data into an Excel file, you get the 1143 number. Clearly, the graph show 558 as a max. I don’t know why the difference. But I’m using the downloaded data in my analyses.
As I am trying to figure out some of these numbers and math, I just wanna point out one thing: I am “anti-p” in Moscow hotel rooms. [Waits for feigned laughter. Sound of crickets] I say I’m “anti-p” in….. oh nevermind.
@ Hanson and Menzie
The 7-year daily spikes at over 1500—I wonder if there’s some kind of mistake on the Daily/Monthly as far as the download numbers?? I think the most annoying thing about the graph is the won’t let you “pause” it between graphs, unless I’m not seeing it. There’s also a big difference in the scale number for “7-year” and “All”. The Daily “All” spikes around 960.
No, UK monthly value is 558.22 for both 7 year and all (July 2016, 5th pip). The moving indexes used to bug me but I have gotten better at a quick read. And usually keeping curser on chart holds it.
Ed
Menzie
I went ahead and checked few other peaks and one valley. Your Monthly UK EPU consistently has approximate double the value found on the PolicyUncertainty front page Monthly UK EPU index (5th pip). Feel free to use your own values, but if you are right you found a major flaw in by the developers. Because thay have more checkers, I will continue to use their chart.
Ed
Ed Hanson: I will inquire of the authors. FYI, the series I am using is the same series that FRED has online, so I suspect the series I am using is the default or more authoritative.
Ed Hanson: The authors have responded to my query. The series you can download is the “official” series in the sense that it is accessible, but is based on only two newspapers. The series graphed is broader, but has not yet been made accessible. I am using in my analysis the series that is downloadable and is used by everybody else.
“My visual and general note of spikes of uncertainty has more meaning and correlation than your over mathematical treatment which feigns accuracy.”
In other words: “I win because I say so.” The obvious answer is “Says who?”.
You simply have no standing to make such a claim.
It’s probably worth mentioning that the methods of statistics are useful in part as a check on people’s sense that they see patterns and “evidence” where none exists. Your claim that your own eyeballing of some wiggly lines is more reliable than statistics is just silly.
I’m not going to pretend I understand all of this post, because I don’t. I grasp some parts, not others, and I think I get some of the broader points. One thing I will not do, is pretend I know sh*t that I don’t. And other than adding to the blog by “prodding” Menzie to get more detailed and explanatory about this stuff, I don’t view it as useful to pretend you know things you don’t. You make a fool of yourself. And I’m not going to name names. because regular readers know who the commenters are that do this continually, and the obvious doesn’t need to be spoken out/written out.
BTW, You can find the Forbes Rigobon paper with some searching if you don’t have a Wiley subscription.
Apparently, Ed is quite content assuming the role of recalcitrant red headed step child when reacting to the scary doctor’s presentation of economic(s) realities.
Menzie’s David Letterman humor on exhibition again:
“Now, I’ll go back to defending the use of logn(.), aka ln(.).”
Speaking of humorous situations, I think Nikki Haley just found out what happens when you flirt and dance with Satan in a cynical career move:
https://www.nytimes.com/2018/04/16/us/politics/trump-rejects-sanctions-russia-syria.html
Sick perv note from Moses Herzog to Nikki Haley:
“My Dearest Nikki, I heard you were hanging out with that Queens NY guy with the dead orange squirrel on his forehead. Come on Nikki, you know those frat boys are trouble. You know he was voted “Most Likely to F******* With Multiple **** Girls” his senior year at the Douche Prep Academy, didn’t you?? I find you sexy in that East-Indian bookish girl kind of way (which I totally go for). But I think the part of your brain dedicated to Machiavellian maneuvers has had a large malfunction. Call me Nikki, I can help you “1-800-wite-prv”. That’s “1-800-wite-prv”. Thanks Nikki and remember, I’m doing this for the needy children of Congo. Signed, Moses”
[edit for content by MDC]
Damn man, this is like Jimmy Kimmel, I think it looks more dirty with the asterisks. I guess Menzie gives me a longer leash than I deserve.
https://www.youtube.com/watch?v=7ifdm7Te1fg
Dear Menzie,
This is going to be one of the dumber comments you will receive. But if you are using correlation coefficients, which I also expect to use shortly, can you relate the package you are using to get them? Is it EViews, or EXCEL, or something else? This makes a marginal difference.
Julian
Julian Silk: Excellent question. We know Excel has some idiosyncracies, and rounding problems especially when applied to matrices. I used output from EViews.
For whatever it’s worth coming from a regular joe six-pack I think that was a great Question. I was tempted to ask Menzie the same exact question, but I try to keep the questions sparing for better chance of response. I was going to ask if anyone knew some good quality “freeware” packages or “open source” type stuff that was a number cruncher like Excel. But I think Menzie’s endorsement on this particular topic means something.
Frankly, after experiencing the “blue screen of death” for what seemed like half my damned life, and seeing how Microsoft single-handedly destroyed the greatest browsing program in history (Netscape), I avoid them like the plague. Those SOBs would have to pay me to use any of their crap programs.
I just DL’ed something called “Apache OpenOffice”. Not sure how this compares to Apple’s “Numbers”. I wager it has some of Excel’s same glitches and is not as good as EViews. But beggars can’t be choosers, and you can never have too many number crunchers. If anyone has any “word of mouth” comments or thoughts on “Apache OpenOffice” or on this topic of programs that crunch numbers I would love to hear them in this thread or any other more recent threads. I don’t like using the cloud so, to find one that jives with Excel and I don’t have to be online to use, I feel enthusiastic and am “getting my nerd jones on”.
“I’ll go back to defending the use of logn(.), aka ln(.)”.
True albeit sad story. The Canadian Revenue Agency’s first attempt to challenge intercompany loan guarantees as being supposedly excessive relied on some “financial expert” who modeled out what the fee should be as ln(x) but then used Excel’s log(x) not knowing the default is base 10 not the natural log. When the taxpayer realized this error, they put his assumptions into Excel and did the right calculation which supported the taxpayer’s position.
Of course this stupid litigation went on for years with enormous legal fees. The rumor mill has it that the Canadian Revenue Agency’s former lawyers are now working for the White House.
As an aside, Menzie misrepresents the concept of “appeal to authority” in the linked post, Anti-Intellectualism in American Blogging. When Menzie mentions reliance on the Kansas City Fed’s forecasts or asking one’s doctor about a prescription, he describes accessing relevant expertise as part of an analysis. Appeal to authority is a technique to close argument and refute analysis by citing the opinion of an authority figure.
For example, if I use the Kansas City Fed’s forecasts appropriately and with consideration for the forecasts’ uncertainty along with other data and sound analysis to reach conclusions, that is proper. It is not appealing to authority, but is a necessity for any endeavor that involves information outside of one’s direct experience and thoughts.
However, if you perform an analysis and I simple declare that it does not comport with a Kansas City Fed forecast and thus must be correct, I am practicing appeal to authority.
“incorrect”…
Moses Herzog You asked about freeware and Apache. I’ve had some experience with Apache and its sister LibreOffice. They are very similar to Excel, but a little clunkier. But the functionality is about the same. The big problem I have with Excel and Apache/LibreOffice is that they give the user tools to do some regression analysis, but they don’t give the user the tools needed to test whether or not the regression makes any sense. The diagnostics are at least as important as the regression itself. So you end up with folks doing all kinds of brain dead analyses. For example, you might want to look at autocorrelation or heteroskedasticity checks. Those just aren’t there with Excel type products.
If you’re looking for a good and relatively easy piece of freeware for doing econometrics, let me recommend a few: JMulti, GRETL and “R”. JMulti only covers time series analysis and doesn’t have anything on cross-sectional or panel data analyses. But it’s pretty intuitive and written by some highly esteemed econometricians. The authors also wrote a handy book on time series analysis (undergrad level) that works through examples using JMulti.
http://www.jmulti.de/
GRETL is another econometrics tool that is very similar to EViews. In fact, for some tasks I prefer it to EViews. It also includes some nice historical data sets.
http://gretl.sourceforge.net/
And the big daddy would be “R”.
https://www.r-project.org/
“R” is extremely powerful with lots of packages you can download. Many of the packages are described in the Journal of Statistical Software.
https://www.jstatsoft.org/index
The problem with “R” is that it is command based and the learning curve can be a bit steep, although there are lots of books on “R”.
You could also look into Python, but I’m not all that familiar with it.
Finally, the other day we were discussing machine learning and SVMs/SVRs. There are “R” packages that use the same libraries as MATLAB, but another popular tool in Europe is Tanagra. It was developed at the University of Lyon and is big on machine learning. I’ve only had limited experience with it, but it is probably easier than using the “R” packages if you ever want to do machine learning stuff without the expense and hassle of having to work with MATLAB…and I would do almost anything to avoid MATLAB!
https://en.wikipedia.org/wiki/Tanagra_(machine_learning)