- Population mean
- Sample mean
- Population standard deviation
- Sample standard deviation
- Standard error
- Administrative data
- Survey data
- Point estimate
- Confidence interval
- Sampling bias
- Reporting bias
Now, let’s begin. Here is a graph of estimates of cumulative fatalities in Puerto Rico over time.
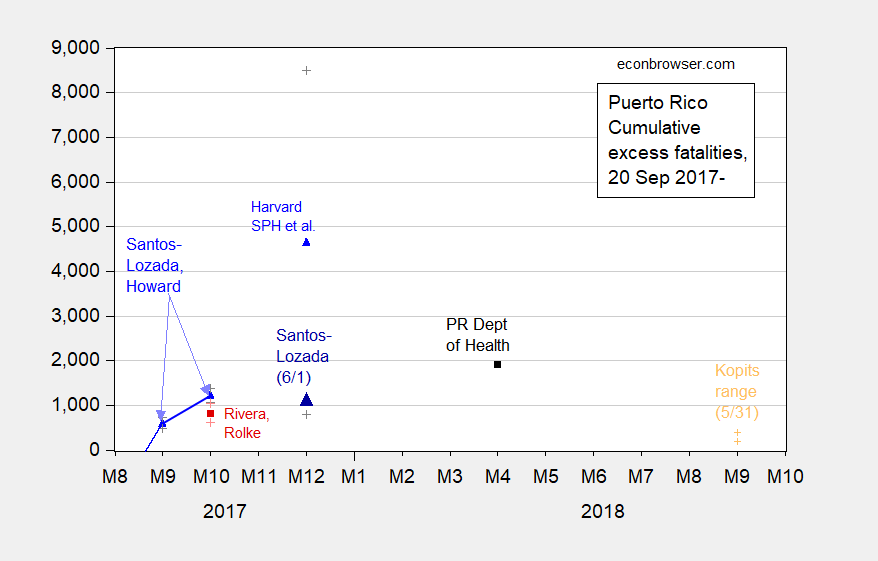
Figure 1: Estimates from Santos-Lozada and Jeffrey Howard (Nov. 2017) for September and October (calculated as difference of midpoint estimates), and Nashant Kishore et al. (May 2018) for December 2017 (blue triangles), and Roberto Rivera and Wolfgang Rolke (Feb. 2018) (red square), and calculated excess deaths using average deaths for 2015 and 2016 compared to 2017 and 2018 using administrative data released 6/1 (black square), and Santos-Lozada estimate based on administrative data released 6/1 (large dark blue triangle), end-of-month figures, all on log scale. + indicate upper and lower bounds for 95% confidence intervals. Orange + denotes Steven Kopits 5/31 estimate for range of excess deaths through September 2018. Cumulative figure for Santos-Lozada and Howard October figure author’s calculations based on reported monthly figures. [Figure revised 6/3]
Recall, the official count of Hurricane Maria related deaths was as of yesterday 64 (and perhaps still is).
The estimates are derived in different ways. How does one understand the strengths and weaknesses of each?
First, a definitional issue. The 64 count is I believe an estimate of direct deaths due to the Hurricane (e.g., flying debris, drowning, etc.). It does not include for instance deaths due to electricity supply interruption (which could be categorized as “indirect”, see discussion here).
With that prefatory remark made, what is true is that most researchers attempted to identify excess deaths associated with Hurricane Maria, both direct and indirect. In order to do that, one needs to determine what is the normal rate of deaths, and measure what is the currently observed.
With administrative data, the latter is in some sense easy, assuming away biases in reporting and lags that might occur because of bureaucratic and/or communication constraints. The former requires a model — say averaging over the previous six years — as in Santos-Lozada and Howard. Even then, recalling the PR population is declining over this time, means that this averaging procedure is not necessarily uncontroversial. The sample mean (arithmetic average) of the monthly data over the years (say October) is an estimate of the true population mean (I talking frequentist here, not Bayesian), which is unknown. Santos-Lozada and Howard used administrative data, and in fact used the upper 95% confidence interval (based on the calculated standard error, which in turn is calcluated using the sample standard deviation, which is a function of the population standard deviation) for their estimate of a given month’s mean deaths, in order to be conservative (I used actual 2017 reported minus estimated mean in my calculations in the above graph). Had I reported their more conservative estimate, then the cumulative thru-October number would be below Santos-Lozada’s current estimate for cumulative excess deaths through December.
The Rivera and Rolke study uses administrative data, but assumes a different distribution (i.e., does not assume a Normal distribution), and has to estimate part of the October numbers, so differs, but not essentially from the Santos-Lozada and Howard estimate.
Both of these studies based on administrative data have confidence intervals, but it’s important to understand that the confidence intervals have to do with the error in sampling assuming the data are reported correctly (no measurement error).
The big outlier is the Harvard School of Public Health study published in the EJMR, in terms of point estimates. The point estimate of 4565 is surely headline grabbing. However, the authors explicitly noted the 95% confidence interval, from 793 to 8498 (and in reputable publications like the NYT, reported. Here, the number of respondents is small relative to the population, so the sampling error is large, and the resultant estimate of excess deaths corresondingly imprecise.
So is the Harvard School of Public Health “garbage”? I would point out that in their survey design (the team didn’t just go out to Puerto Rico and willy-nilly interview people), they could control for things like remoteness.
In the administrative data, one in principle could do that, but to date, all I know is that the deaths are recorded as the information comes in. We (or at least I) do not know if there is a bias in reportage — are deaths incompletely reported because telephones are not working, and very few people can travel over broken bridges and swept away roads? I think this is potentially very important, given the distribution of these effects is not random. (The lags in reportage is probably not random either; and even in the US in non-crisis situations, the QCEW data lags CES estimates by about six months!)
From the Kishore et al. (2018) in the New England Journal of Medicine:
We found a strong positive association between remoteness and the length of time without electricity, water, or cellular telephone coverage (Fig. 3A). On average, households went 84 days without electricity, 68 days without water, and 41 days without cellular telephone coverage after the hurricane and until December 31, 2017. In the most remote category, 83% of households were without electricity for this entire time period (Table S2 in the Supplementary Appendix).
The distributions around these estimates were often bimodal (Fig. S5 in the Supplementary Appendix), particularly in remote regions, which suggests that households either recovered services relatively quickly or not for several months. Many survey respondents were still without water and electricity at the time of sampling, a finding consistent with other reports.
This suggests to me we may see continued rise in fatality counts attributed to months past, perhaps surging when full power and road traversability is restored — something that might be delayed considerably should another hurricane or tropical storm hit Puerto Rico.
Finally, for those who still have a visceral distate for survey data — if you have been citing the labor force participation rates and employment numbers at the state level, it would behoove you to know you are relying upon survey data, and not particularly large samples, at the state level.
Update, 6/3 6:40PM: NotTrampis refers me to Andrew Gelman’s excellent analysis of the Harvard SPH study, and I am glad to share it with you.
This (the above post) is what teachers do. “Professor” or “Doctor” is really just a slightly more respectful way of saying teacher. They have earned that title through usually higher levels of education and/or more specialized knowledge in the field they teach. Tenure is not as “easy” to attain as it was in years passed. (i.e. it’s a pain in the ass and often a backbiting and backstabbing process among your peers, some of which “you”, surprise, may not get along with. All for often relatively low pay for the hours and work involved.
On top of all that, you have guys like Menzie, guys who do things like this blog, which benefit the general public, benefit “joe-six packs” like me. He doesn’t “need” this blog to teach his class. He can easily make this stuff available through other means, or even make a password only available to his students. Can some of you very “perceptive”, “deep”, and “awe-inspiring” commenters with your fantasyland math PhD’s and fantasyland stats PhD’s get the point??—That Menzie provides all this stuff FREE because maybe he is a good guy, cares for society in general, and probably figures a better educated electorate makes for an electorate that makes better choices???
Or would you prefer to insult Menzie and insult his work for absolutely ZERO reason. I am very afraid I already know the wretched and gloomy answer to that question. I just hope the ones who enjoy this blog and appreciate the utility and small oasis of intellectual integrity it provides in the wasteland of MAGA , don’t eventually get punished for it by Menzie just saying he’s had enough.
Of course, if you have the type of personal character which allows you to walk around trying to dupe people into thinking you have a degree or any attachment to the University of Princeton, which you don’t have, everything I said, as far as you see it in your own mind is null and void.
“if you have been citing the labor force participation rates and employment numbers at the state level, it would behoove you to know you are relying upon survey data, and not particularly large samples, at the state level.”
This is an interesting point in light of Republican efforts to provide waivers to the Obamacare law in order to institute work requirements for Medicaid in Michigan, Ohio and Kentucky. Curiously, Republicans want to allow exceptions to the work requirements in counties that have higher than average unemployment rates. These counties tend to be rural and overwhelmingly white — quite a coincidence, I’m sure.
But as Menzie Chinn points out, unemployment rates at the state level are based on relatively small sample sizes, let alone at the county level. Rural counties might be represented by an unemployment sample of only 30 households. The BLS generally will group several rural counties together just to get a reasonable sample size. So the Republican plan for creating work exemptions using uncertain unemployment rates at the county level is based on statistical ignorance.
Republicans — dumber than dirt. Or could it be they are clever racists. Hard to tell the difference.
This morning I made the mistake of watching Good Morning America while enjoying that first cup of coffee. I guess it’s better than watching Fox & Friends. Unfortunately the reporter (or should I say “presenter”?) mentioned the Harvard study, saying that it concluded at least 4600 people died. So somehow a point estimate becomes the bottom range estimate.
I’ll tell you a cute little trick. I like Bloomberg over most other sources of news. Certainly over regular network stuff. Now, not that long ago you could access Bloomberg TV for free online with no subscription. I was semi-amazed the free access lasted as long as it did. But roughly a month ago, Bloomberg put up some kind of paywall on the BloombergTV where you have to be subscribed in some form or fashion. Being the king of the cheapskate moochers that I am, I’m semi-good at weaseling around these things. And I’m selfish enough, I hesitate to share, as if enough people use it, they will yank it down. But where they have it blocked inside the Bloomberg—you can access all of that free and “Live” on the Bloomberg channel on Youtube, 24hrs a day free. How long that will last in our new Ajit “Bribery Makes My Rules” Pai world, your guess is as good as mine. Other than that you always have NPR and PBSNewsHour, which you can DL the podcast for ANYTIME of coffee-drink partaking.
Between David “I Should Have Been A P*rn Star” Muir, and Jeff “Boy Scout With a Dead Soul” Glor, your brain cells will be zapped gone in no time, and you’ll wonder to yourself “When did geriatric pills actually establish world domination??”
That is pretty bad but remember that the Trumpsters think at most 64 people died.
I repeat everybody go and read what Andrew Gelman has written about the journal article. Read the comments as well.
you will need to understand the above terms otherwise it will be a waste of time.
It is a must read site if you wish to remember the stats you did back at Uni. It is on my sidebar.
Providing a link never hurts. He also has an RSS feed for any RSS Reader junkies out there.
http://andrewgelman.com/2018/06/01/data-code-study-puerto-rico-deaths/
After only a casual skim of it, I agree it seems to be informative. And you know how I hate to agree with you derned dadgum conservatives.
I don’t think Not Trampis is a “derned dadgum” conservative. I suspect his only vice might be a fondness for Foster’s, but that’s about it.
You may have done the impossible and uncovered an even worse crime.
https://youtu.be/jF5dZRooRWQ?t=20s
no I actually drink Heineken. I loathe Fosters. Love our wonderful wines though.
@ Menzie
Menzie, I may actually have a semi-intelligent question here for you, and if you can believe it coming from me, it’s related to this post. Do you have any issues/problems with Nashant Kishore using a Poisson distribution?? And do you know why they would have chosen this over other types of distributions??
Maybe it’s NOT the use of Poisson that is the problem?? My question was really related to this, which I am copy/pasting from Andrew Gelman’s blog verbatim.
” …….but then in the statistical analysis they don’t use their weights or account for clustering at all! Which makes me wonder why they were talking about the weights at all. They also get a standard error for the number of deaths using the Poisson distribution: That ain’t right! What you’re supposed to do is estimate the rate in each cluster and then use the cluster-level analysis to get your estimate and uncertainty. ”
So, Menzie, do you know what Gelman is talking about here??—>>and is Gelman being “nit-picky” or does he have a legitimate contention?? I’m actually looking more for your personally gauged opinion here and not necessarily the “textbook” answer. Although I’ll take either type of answer you care to give.
Moses Herzog: I think epidemiologist often use Poisson because they are working with count data – recall they have a few number of observed deaths, so I can see why a Normal is not right. Now whether that’s best, I don’t know — my work is with time series and panel data, where there are large numbers of continuously distributed observations.
Moses Herzon This is a little nerdy, but with a cluster analysis the first task is to try and fit observations into clusters. To do that you try to find groupings of observation that minimize the variance within each grouping, but maximize the variance across groupings. For example, if you wanted to separate individuals into families, you’d identify characteristics like eye color, skin color, height, weight, etc. People that were similar in those characteristics are probably members of the same family. But you’d also want to work things the other way to maximize the differences between families. In that kind of analysis you wouldn’t be interested in the variance across all members of the population; what you’re really interested in are the first and second moments within each family and then the first and second moments of the families within the total population. Confused? If you’re familiar with ANOVA, then think of ANOVA in reverse, which is how it’s often described.
In the Land of OZ one does two stats subjects and then two econometric subjects when studying economics. I do not recall having anything to do with poisson per se’ until I eventually went to business school.
As Menzies says most stuff in economics is utilising time series or panel data.
I might add both Andrew ‘s blog and this one are on my sidebar.
Having standards on an economist blog – a novel concept?! Mark Thoma should do the same. One troll over there was going off as to how high tech companies hide the cost of their employee stock options which would inflate their reported profits if true. But it’s not. When I pointed that out this troll pretended SFAS 123 did not matter. Really? When I provided him a link to a clear discussion he get angry and went back to his bogus claim with Facebook as his prime example. So I pulled the disclosure of these expenses in Facebook’s 10-K filing. So what did the troll do? He thought I was referring to some 6.2 mile road race and threatened to attack me the next time I went for a run. Yea EconomistsView gets a lot of comments but most of them are overheated waste of time.
Menzie, the attempt to have a process discussion was a failure unless you had another goal.. Except forgthe Not Trampis’ reference which doen’t treat the Harvard study well all I see is the all too common snark and meaningless comment from the same bunch.
CoRev: Not Trampis refers us to Gelman which is not entirely critical; I’d be happy to get a referee report that positive.
That you make this assessment tells me you are ill-equipped to have any sort of technical discussion in an academic setting.
Menzie, “… you are ill-equipped to have any sort of technical discussion in an academic setting.” I’m sorry you feel that way. At my stage in life the blog world is surely as close as I will ever come to another academic setting. Very few of us live in that world anyway.
As an academic I can see how this is an interesting and novel approach for you, but is it useful to policy makers or legislators in prioritizing and funding aid? Even Gelman has his doubts: ” Policymakers should be combining what they learn from different sources.”, while agreeing that it’s an interesting approach but maybe inadequate for any precise estimating: “So I think Rafael is right that, if you’re going to do this sort of survey, you should look at all the information you can and not get stuck on any particular number.” Additional information on general feelings for it are contained in the Gelman comment section.
So Gelman being not entirely critical is not a measure of usefulness for legislators funding aid, and of limited use for policy makers. Maybe the Harvard study is not yet ready to leave the academic setting, and it is fine if you use it as an exercise in your class room.
As an aside on science, the Harvard study is an excellent example of transparency. You can probably guess why I mention that.
Moses Herzog In the past you’ve expressed some interest in free econometric software. The “R” package is very good. You might want to look at this handbook for “R” in econometrics:
http://www.ecostat.unical.it/tarsitano/Didattica/LabStat2/Everitt.pdf
In particular, you might want to look at Chapter 15, which provides a fairly simple example of cluster analysis in “R”. There are a bunch of “cluster” packages, but a couple of good overviews are here:
https://cran.r-project.org/web/packages/mclust/vignettes/mclust.html
If you’ve ever worked with machine learning tools (e.g., face recognition), you’ll notice the similarities with cluster analysis. You’ll also notice that it’s not all that different from principal components analysis.
The Journal of Statistical Software website is also a good reference. For example, here’s a vignette describing one of many cluster packages in “R”:
https://www.jstatsoft.org/article/view/v050i13/v50i13.pdf
@ 2slugbaits
I greatly appreciate these links, and am grateful you put them in the thread. Some of these terms I have heard before (the term cluster and Poisson for example) and have probably even worked with them on exams many years ago. I took 3 stats classes in college, one was a 101 type, I think one was an intermediate, and then one elective I took on Quality Control which required the stats as a prerequisite. I even went through a short phase where I was quite interested in the topic of quality control, but fascination was as far as it led. I always found W. Edwards Deming’s lectures and some sections of his books mesmerizing (no joke). ANOVA is even ringing a very faint bell somehow, but I can’t swear that I had ever worked with it. I’m definitely going to be following up on some of these terms so I can understand Gelman’s point in the text I pasted above and also for my own edification, so hopefully when this topic arises again I will know. And make no doubt about it I will be perusing those links on “R” you were kind enough to share and I genuinely appreciate it.
Dear Menzie,
Let me also thank you for the R links. My only point, and yes, it would be nice to think that the sample is representative, and of the statistically necessary size, etc., and the Poisson assumption is valid, etc., to produce a good estimate of the population mean, is the causes. The Harvard study seems to have an unusually large confidence interval or estimated variance. It might be the case that it can be broken down into causes – drowning, exposure, pollution of water sources, heart attacks in trying to escape, etc. It is morbid to look at such stuff, granted, but this is essentially a morbidity study. Did the Harvard people try to make any guesses as to the causes of the deaths?
Julian
I do feel the three posts by Menzie on this topics are instructive for those who have not studied Statistics as their major. I have combined them with Andrew’s article as well at my modest blog. ( to paraphrase Winston I am a modest man which much to modest about!)
I have added the comments are quite good at Andrews blog and very helpful. Not so here. too much ignorance and snark.
I have not put it in but I shall now but I think it highlights the difference between statistics and econmetrics to which Menzie alluded to.
Thank you Menzie., I like to continue to learn.
When a Democrat is in the White House, Republicans go on and on about Kenya and the most ridiculous nonsense one could imagine for a cartoon satire. Republicans call a man “Muslim” who attends Protestant church regular and follows the tenets of Christianity to an extent so much more than Trump, it probably exceeds the entire volume of the Pacific Ocean. When a Democrat is in the White House, Republicans mention 1776 and how “it’s the right of the people to question government” “It’s the right of the people to assemble”. The “founding fathers” and the pamphlets they made excoriating British rule.
But when a “liberal” or a Democrat questions the utter nonsense, not to mention mathematical blasphemy put up by some right-wing illiterates, it strangely (more like it, absurdly??) becomes “snark”, “rude”. “snowflakes” and on and on and on……. Seems the reality is Republicans are more than happy to dish it out, but cannot take it.
Here’s my advice —-skip the comments section of any blog that you don’t like the comments—-OR GROW UP AND JOIN THE ADULT WORLD
sorry mate but a person can criticise a comment , more so when based in ignorance, and not be snarky. Call me old fashioned and I am but I like comments that leads to me having a better understanding. slugs over the years has done this. When he does this he is much better than when he is snarky. PGL is unrecognisable from the knowledgeable person at econspeak.
Not Trampis: Historically, pgl has been very restrained. However, in my humble opinion, the frustratingly obtuse remarks by some commenters have driven him to distraction. I admit to feeling his pain…which motivated me to write the “Please, do not comment…” post.
Not Trampis & Menzie, econbrowser has been an outstandingly bright spot in the blog landscape where open discussion has been allowed if not encouraged. Recently its tone has changed largely due to its commenters. The pgl I have watched for years almost always has acted the way he does here. I only occasionally read Econospeak then and never now. He was banned from Angry Bear, where he was a contributor also, for his comment style. 2slugs and I have jousted for years at AB and here. He has always been capable of arrogance and not as often snark. I, a conservative, usually react in kind when so confronted, and I think that is true for all of us. Only a few commenters are consistently snarky or use ridicule.
I noticed a profound change in the arrogance from several to many liberal commenters after the Obama election. I would call that the gloat factor when one of their own liberal left was elected along with a more liberal Congress. It lasted only as long as the Congress stayed Democratic. After which the ridicule began in earnest against conservatives as their progress(ive movement) was stalled.
With the Trump win there has been a great deal of added anger from the liberal left as Trump did away with many of their past gains. Since Trump’s win anger and ridicule has gotten worse, and each Trump successes seems to lead to its strength building. Trump (and conservative) bashing has become the norm. Not Trampis, you too have often been a Trump basher. Many, many blogs managed by liberals have out rightly banned or driven off most conservatives resulting in echo chambers of like thought.
Menzie, I fear you too have succumbed to anger and conservative bashing. From a conservative’s view it appears to be the result of Trump’s greater success compared to Obama’s. Econbrowser has been an outstandingly bright spot in the blog landscape where open discussion has been allowed if not encouraged. I hope it continues to be so.
NotTrampis: Thank you for your suggestions and comments. The Gelman reference was very helpful for understanding more fully the aspects of the Harvard SPH study. I have added a link to the Gelman piece to the end of the post.
Kopits range is incorrectly shown, which would be apparent if you had read the associated article. My specific statement was this:
“At the year horizon, excess deaths seem likely to settle in the 200-400 range.” I defined a ‘year horizon’ as on Oct. 1, 2018. That is, Month 9, 2018 on your graph, based on ‘as of’ data for December 2017 provided by the Puerto Rican government. If you want to extend your graph and put two dots at Mo 9. then that is what I actually wrote.
Of course, this was based on December statistics which were published in the Latino USA article. The May 31 release of deaths revised December up materially, although it did show a decline, as did January. February and March were up. April and May data I think remain too soon to use with confidence. Thus, it would seem that the Oct. 1 number would be higher than expected, but I am unable to make a fixed forecast at this point, as we do not have an unambiguous peak for excess deaths at this point.
More coming…
Steven Kopits: Thanks. I’ve revised the graph per your suggestion.
Thank you.
My analysis is up.
https://www.princetonpolicy.com/ppa-blog/2018/6/3/pr-releases-new-data-deaths-1400-not-4600
Steven, i liked your revised graph. I wonder, at some time the “indirect deaths” time frame must end for hurricane Maria as questioned by several commenters in the Gelman article. When the end is is still to be determined. It is clear that the PR conditions before the hurricane can also be blamed, but the hurricane’s impacts on deaths in PR will be temporally extended compared to more stable/prepared/experienced areas, Florida and Texas for example.
As for your conclusion: ” It is not yet impossible that deaths settle in our expected range, but given that a firm peak is not yet visible, excess deaths are likely to be higher than our expectation, and possibly materially so.” may prove the value of the Harvard approach, modestly modified with experience, in some limited conditions. My intuitive guess at this time is the PR actuals will approach, but not exceed, the mid-point of the Harvard mid-range estimate.
There’s nothing wrong with trying a survey approach, and nothing wrong with a drive-a-truck-through-it confidence interval. The problem is that the 4600 number was published by every major news outlet in the country when the number was very likely to be wrong and this should have been known by the authors of the study.
The clock is ticking on Harvard. Politifacts spent a half hour with me on the phone this morning.
Steven Kopits: You write “the number was very likely to be wrong and this should have been known by the authors of the study.” Unlike your 200-400 number, the Harvard SPH confidence interval encompasses the current estimate of excess fatalities for end-December as tabulated by Santos-Lozada and pretty much any one else.
I’ve spent more than half-an-hour with Politifact in the past, on several occassions. What does that mean?
Elevated deaths through end-November may plausibly be attributed to the hurricane.
Both December and January were below the previous year, so excess deaths may have ended in November.
On the other hand, February and March were above average. Perhaps this was due to the hurricane, perhaps something else.
Approximately 1250 of the 1400 excess deaths to year-end occurred in the 40 days from the hurricane. I do not know how much of this could have been avoided, as most of it is attributable to the sustained loss of power. Of course, PR utility PREPA had filed for bankruptcy just two months before the hurricane, so response was going to problematic. Given the punch of the hurricane and the mountainous nature of the island, I cannot say what the counter-factual would have looked like. But I think many, and probably most, of the deaths would have occurred under any plausible scenario given pre-existing conditions on the island.
PR is vastly different from any of Texas, Florida or Key West. In all those cases, utilities had both the funds to rebuild and logistics support which can be brought in by road on short order. PR had neither. As for Key West, the causeway remained intact, the islands had been evacuated preemptively, and we are speaking of a few tens of thousands of people, not 3.5 million, as on PR. PR was going to be harder, no matter what.
A head-to-head comparison with the US mainland is not feasible. This is neither to endorse nor condemn FEMA efforts in PR, merely to point out that an apples-to-apples comparison is problematic.
Worth noting that Kopits new article says that the Harvard study is wildly inaccurate because its central value is 233% higher than the current “official” number but within the study’s 95% confidence interval. But Kopits used his number of 200-300 which is off by 470% and explicitly not within his confidence interval to call the Harvard study “garbage.”
As usual, Kopits jumping to his political conclusion and failing to check his work, just like he did when he claimed that Obamacare cost $35,000 per person.
We await Kopits apology for calling the Harvard study “garbage.” I’m not holding my breath.
Joseph, you see to misunderstand what the Harvard study is saying:
The study authors said this:
“…Does your study say that 4645 died?
No. We provide a 95% confidence interval of 793 to 8498, and 4645 falls in the middle of this range.
What is a confidence interval?
We implemented an approach that generates a confidence interval that has a 95% chance of including the actual death count. …”
Moreover you seem to misuse Steven’s numbers. His range has been 200-400 not 300 as you claim. Steven’s response from above: “At the year horizon, excess deaths seem likely to settle in the 200-400 range“., and this was from the earlier release of PR data. With later data releases Steven has updated his estimates, you have yet failed to credit these estimate changes. It is positions like this that convince me you are being irrational.
We do not yet know whether my 200-400 number will be wrong, Joseph. However, given the revised data from the PR government on Friday night, I think the excess deaths at the year horizon could come in materially higher. The data does not permit an estimate at this point.
See the analysis: https://www.princetonpolicy.com/ppa-blog/2018/6/3/pr-releases-new-data-deaths-1400-not-4600
Steven Kopits: You made a relatively incontrovertible assertion bounded at 200-400 for Oct 2018 earlier on 5/31, without knowing the nature of the data; yet now you say you can’t make an estimate? Hmm.
I do have one question: given the updated mortality figures, how is 200-400 going to be proven right? Will some of the mortality figures be retracted, in your view? Do you really believe that will occur?
Further, you have the temerity to call the Harvard SPH-led study “garbage”, and assert they will be forced to retract by COB today. We’ll know whether you’re right or wrong soon enough on the latter count.
I can’t make an estimate because the latest data doesn’t clearly show a peak. Where is the turning point? I can’t tell.
As for excess deaths. These are deaths indirectly caused by the hurricane, largely due to a lack of electricity. We’re speaking of heart failure, kidney and respiratory failure primarily, which would imply mostly sick and elderly would be involved, Presumably, the most likely to die would be those already near death. As a consequence, we would hypothesize the acceleration of mortality after the hurricane would be followed by a period of lowered death rates. Over some period of time, we would expect the numbers to even out. That’s the hypothesis. I don’t know if it’s true, but that would be my starting point. That’s the logic behind it.
Steven Kopits: But given current excess mortality, how do we get down to 200-400? We’d have to have many months of *negative* excess fatalities, wouldn’t we?
If we assume 1600 is the peak number in March, that gives us six months to get to 400. That would be deaths lower than average by 200 per month. But April doesn’t look that way, and May is still way too choppy. So let’s say we exit May at 1,600.
Then you have four months to get to 400, or 300 / month. Impossible? No. Unlikely? Probably. I need a trend line to make a forecast. Right now, I have an undulating peak. Did I misinterpret December data as ‘preliminary’ when it was actually ‘as of’? Yes, I’ve already conceded that point. I made a mistake, I apologized.
The Harvard team also made a mistake. What do you think they should do?
Kopits, that’s quite the interesting argument that Trump’s depraved indifference to the ongoing tragedy in Puerto Rico merely resulted in “accelerated mortality” by culling the weak and that everything will even out in the long run.
You know, Keynes famous quote saying we’re all dead in the long run was a warning about ignoring short-term effects, not a prescription.
steven, you made a pretty direct and damning indictment of the harvard study when you called it garbage. based upon an analysis you have since revised, and marked with an asterisk that says now you do not know where the numbers will settle. it is really undignified to call somebody else work “garbage” based upon your own work which you have back pedaled as it has become more inaccurate with time. it is fine to produce a report of your own estimates for the deaths, but really poor behavior to attack somebody else’s credibility while your own reports credibility is failing. you do owe the harvard authors an apology.
I would strongly encourage the Harvard School of Public Health to either circle the wagons or pull the study.
Here’s why. WaPo was on the story on Friday, Politifact spent half an hour with me this morning.
By Wednesday, this will be in the conservative media as a ‘fake news’ story. Now imagine a talking heads roundtable with Hannity, a pretty annoyed representative of the PR govt (remember, Harvard is suggesting there are still 3,000 unaccounted for and unrecovered bodies on the island); an author of the study; and possibly me.
Hannity: Mr. Kopits, you broke this story. You’re not an expert in public health, what made you do it?
Kopits: You’re right, Sean. My broader expertise is in data sourcing and analysis. I spend most my time making graphs and explaining them. So I can just look at a graph and tell you if there’s a problem in many cases. I had read an earlier NY Times piece on PR mortality, and I recalled the number as something like 1000 excess deaths through October. Most of the deaths should have been in the immediate aftermath of the hurricane, so I thought it highly improbable that an additional 3,600 deaths would have occurred in the following two months. And if you extended the line from October, it suggests perhaps 1300-1500 deaths in total by year end. So Harvard’s estimate was literally three times the straight-forward extrapolation. You don’t need to be a subject matter expert for that to pop off the page.
Hannity: Mr. [PR representative]: You issued updated excess death counts of 1400 for year-end this past Friday. These confirm Mr. Kopits initial estimates. How confident are you in the death count through the end of the year?
PR Rep: [Pretty confident.]
Hannity: Do you think that there are another 3,000 bodies out there which have not been identified and recovered?
PR Rep: Absolutely not.
Hannity: Mr. Study Author, do you believe those bodies are out there? Are there 3,000 unrecovered bodies?
Study Author: Well, it’s hard to say.
Hannity: So you think it’s possible?
Study Author: It’s hard to say.
Hannity: Well, where are they? I mean, is it old ladies in rocking chairs like the Bates Motel? Do you have any evidence at all?
Study Author: …
Hannity: Mr. PR Rep, the Study Author seems to think there may be abandoned bodies of old and sick people on PR. Do you have abandoned bodies of the elderly?
PR Rep: Absolutely not. The Harvard study team never contacted us, and if they had suggested this at the time, we would have told them they are crazy.
Hannity: to Study Author: But you published 4600 anyway, in full knowledge that it was extremely unlikely on data based through October. And given that we have data that now seems firm through year end, do you stand by your study?
Study Author: Well, it falls into the confidence interval.
Hannity: True, but the entirety of the US mainstream press — including Fox — took your numbers as solid. All of us printed 4600. And that number was wrong. Or was it? Do you still stand by you central estimate and confidence interval, given Friday’s number release?
Study Author: Well, the central estimate looks high.
Hannity: So are you retracting it?
Study Author: Well, the confidence interval…
Hannity: So are you standing by your confidence interval, which states that there is a greater than 50% chance that more than 4600 died? Are you asserting that is still possible? Mr. PR Rep, is this possible?
PR Rep: No.
Now the Study Author either has to double down or fold. If he doubles down, the study will come across as fake news. If he folds, well, I guarantee he doesn’t want to fold live on Hannity. “Well, I think we’re going to have to rethink our central findings.” You absolutely, positively do not want to do that on Hannity.
If you’re the Dean of the Harvard SPH, you don’t want that interview, no matter how it turns out. In the contest between modeled results and actuals, actuals win. The sooner Harvard pulls the study, the lower the losses. If I were the Dean, I would write (or have written) something like, “In light of the release of revised death counts for 2017 issued by the Puerto Rican authorities last Friday, the methodology and results of the Harvard team’s study of mortality in Puerto Rico appear unsupportable, and the authors are therefore retracting the findings.”
I would do that today.
Harvard has to show us 3,250 unaccounted for bodies at year end 2017.
These could be:
Unrecovered bodies: Old and sick people who died and were never found
Found but not recorded bodies: These are bodies in a morgue, for example, which have not been processed
Recorded but not reported bodies: These are bodies which have been processed locally, but not yet reported to central authorities.
Given that we a five months into 2018 and eight months after the incident, it’s hard to imagine that bodies which were recovered had not yet been processed or reported for year-end 2017. But I don’t know that for a fact.
I think one has to assume more than 3,000 unrecovered bodies. That would be incredible.
Kopits: “So let’s say we exit May at 1,600. Then you have four months to get to 400, or 300 / month.”
How perverted do you have to be to say that you killed off all the weak people in the first 6 months so you get credit for fewer deaths in the second 6 months?
A premature death isn’t undone by claiming you didn’t kill someone a second time again later.
And here is the Kopits argument in a nutshell: “Lack of aid killed you in October but didn’t kill you again in June so, on average, you died exactly when you were supposed to, in February. What’s the problem?”
Joseph –
Excess deaths must be calculated through some time period. The Harvard study used the period Sept. 20 – Dec. 31, 2017. The newspapers emphasized that those who died were primarily those with serious pre-existing medical conditions.
Menzie had made a linear extrapolation of deaths, and I pointed out this was not a valid approach if in fact the hurricane accelerated deaths, but did not cause them directly. If the hurricane just accelerates indirect deaths, then those who would have survived, say, another year, will have died, but must therefore be deducted from likely mortality in the coming period. I chose an arbitrary horizon of one year, because you can probably see the effects over a year if at all. So, if we have 1,400 excess deaths and the victims would have lived another five years, then the reversal rate would be 1,400 / 60 or 23 / month. On the base of 2,500 deaths per month, that’s 1%, so probably is not visible in the data. If it’s over one year, then its 117 / month, which would be visible.
From a public health perspective, it may matter. If you have limited resources of money, manpower and logistics, you want to focus on those who would have lived many more years. That may not be nice in some sense, but that’s what triage is all about.
The US, I read, is considering directly influencing the Saudi attack on the main harbor in Yemen, to allow Saudi to run Yemen in the guise of helping a starving Yemeni.
Alpha and beta risks, consumer and producers perspectives. Inferred reality?
Paraphrase Yogi Berra:
“It’s tough to make predictions, especially about the past.”
Acceptor beware?
A lot of terrific things are done in the world by the US most are not the result of not appropriating for a black swan disaster.
What was the status of Puerto Rico’s reporting of deaths before the destruction wrought by the hurricane? How reliable was it? Until that is answered in detail, not assumed, the rest of this speculation and infighting over statistical approaches seems useless. As for decrying the national media reporting a Harvard study that is at odds with the official count, since when has the media gotten anything correct about any story beyond a simple murder? The media is for the most part a business that relies on an audience that craves an emotional bang.