Today, we are fortunate to present a guest contribution written by Simon van Norden, Professor of Finance at HEC Montréal.
‘Big Data’ continues to be the subject of much hype these days, so let me share a small cautionary tale for readers who might be interested in using it for macroeconomic forecasting.
One of the oldest and most-studied sources of big data in macroeconomics is Google Trends, which Choi and Varian (2012) argued was useful in forecasting US unemployment rates, among other things. Another claim made in Choi and Varian (2012), that Google Trends could help predict flu outbreaks, was challenged by Lazar et al. (2014). They noted that Google’s Flu Trends index was doing a remarkably bad job predicting flu-related doctor visits. Many of the problems they identified also apply to macroeconomic forecasting with Big Data, so it’s worth briefly recapping two of them.
- Google Trends, like other indices made publically available, are the product of numerous algorithms and decisions made by engineers that are invisible to the user. The problem for forecasters is that these algorithms are not static, but are tweaked and adapted as time goes on (Lazer et al. noted that the Google Search blog reported 86 changes in June and July 2012 alone). These changes may reflect changing decisions about what the data should capture, or changing properties of the Big Data themselves. (For example, as Twitter Bots become more widespread, and then Twitter tries to curtail their role, measures of topics of interest to users may become more or less accurate.)
- Partly because of the above, the time series provided by Google Trends are not replicable. Historical values available to us now are not the same as those that were available in the past, and values available in the future may be different again. In forecasting, this is often called the “real-time” data problem; the series that forecasters use to test their models are not always very realistic.
To understand how serious this problem is in macroeconomics, Li (2016) tries to reproduce the Unemployment index used by Choi and Varian to forecast unemployment rates. Her Figure below shows that while their original series and hers appear to be highly correlated, much of that correlation may simply be due to seasonal fluctuations.
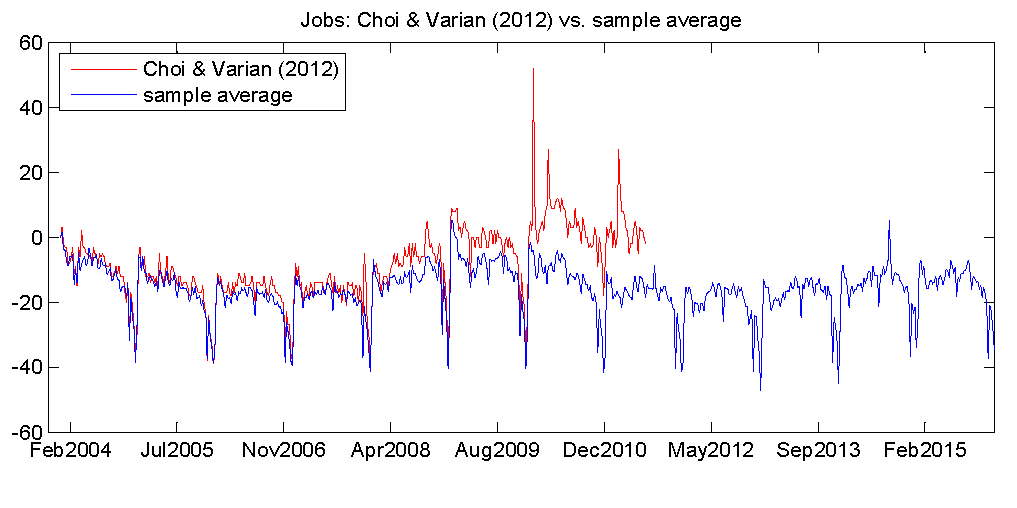
However, my own attempt to replicate their results a few months later (October 2016) produced quite different results.
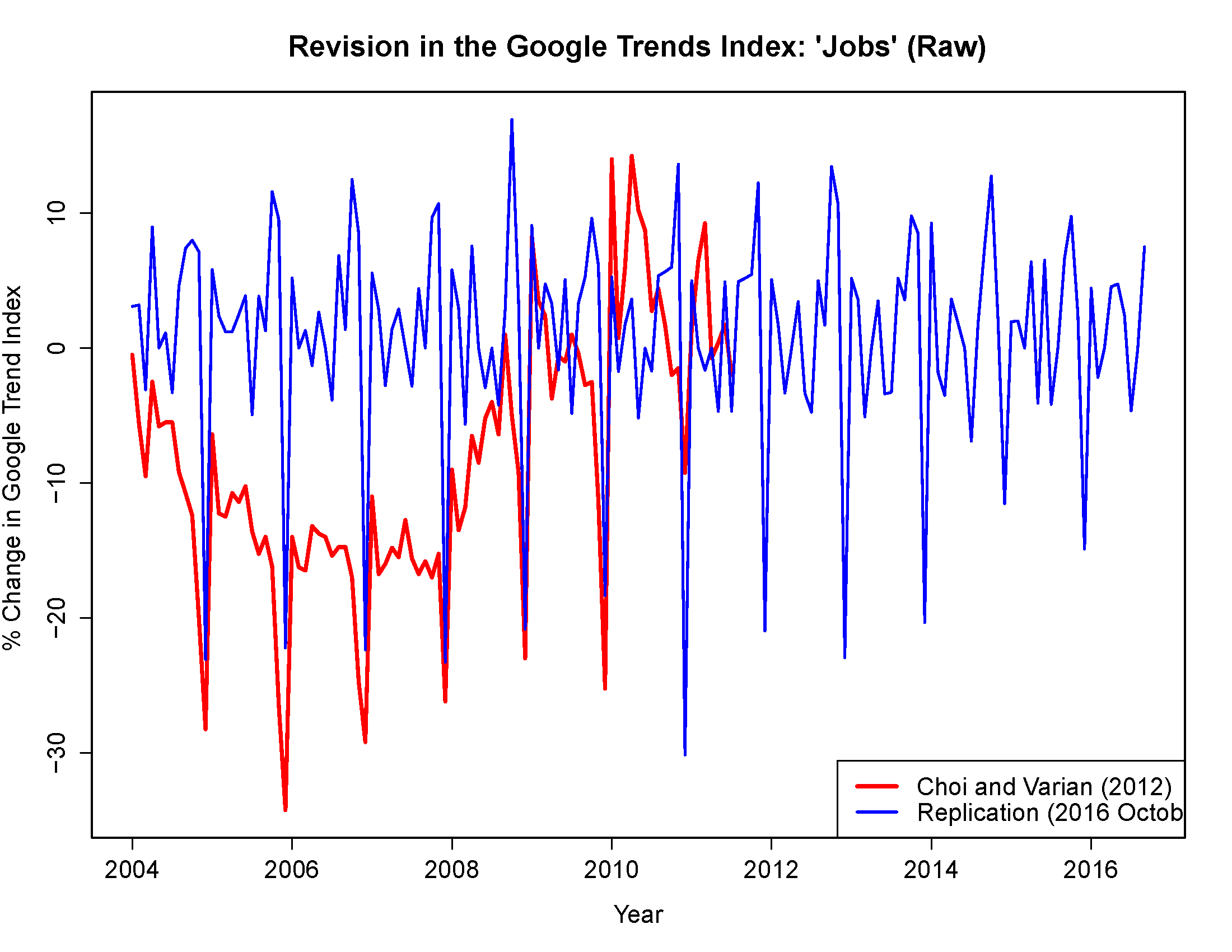
After filtering the data as Choi and Varian did, I’m left with an index that is essentially uncorrelated with their filtered series.
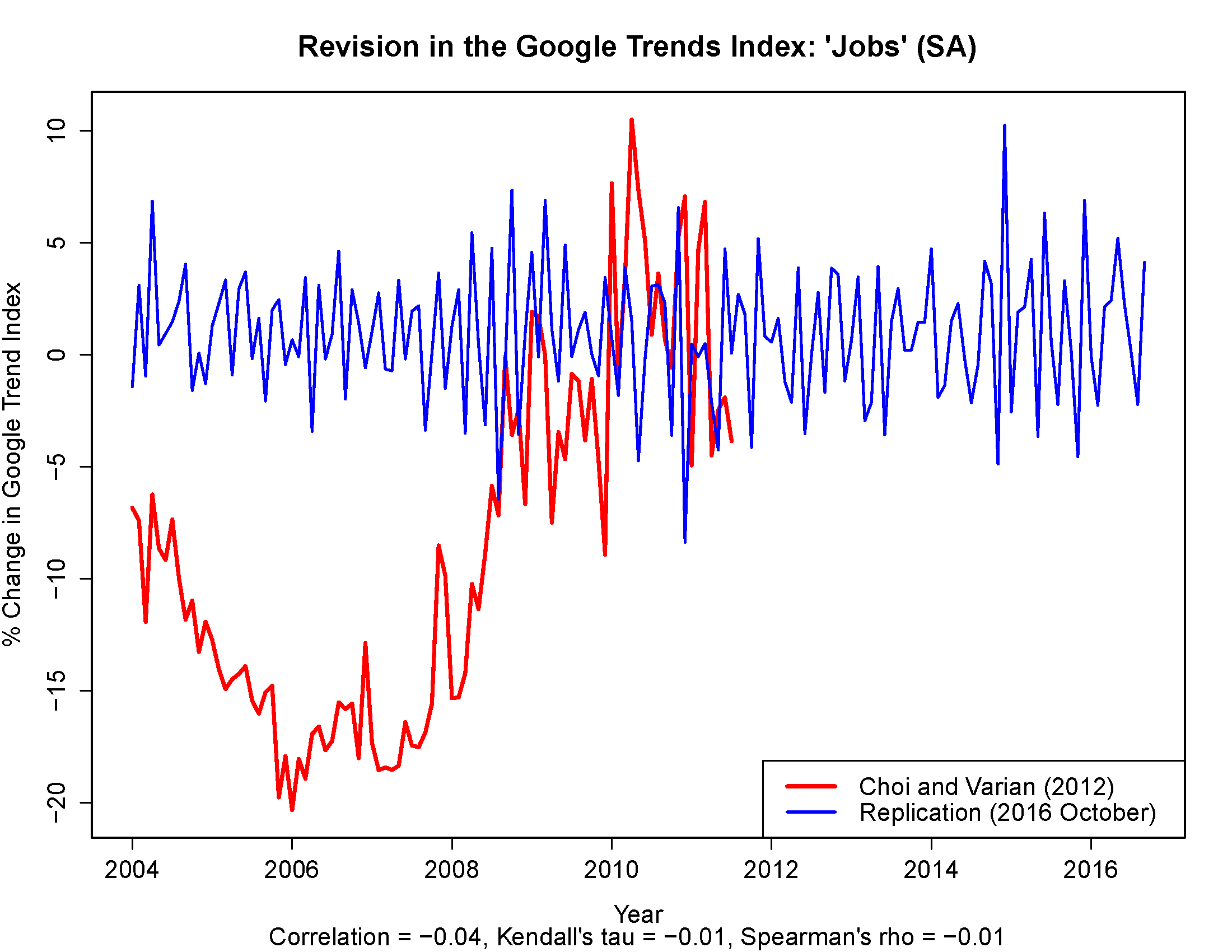
I’m guessing that at some point in 2016, Google decided to put their trends through a high-pass filter which eliminated most of the business-cycle fluctuations Choi and Varian thought that they were capturing.
Of course, not all Big Data, nor all macroeconomic series, suffer from such serious “real-time” data problems. Unemployment rates published by the BLS undergo only trivial revisions; productivity growth numbers can change radically even years after their initial release (Jacobs and van Norden (2016) document some of the problems). But macroeconomic forecasters need to understand the extent of these problems before taking their models out of the lab.
[Disclaimer: I’m the co-organizer of an annual conference on real-time data issues in macroeconomic forecasting. Last year’s conference was hosted by the Federal Reserve Bank of Philadephia and this year’s by the Bank of Spain.]
References
CHOI, H. and VARIAN, H. (2012) “Predicting the Present with Google Trends.” Economic Record, 88: 2–9. https://doi.org/10.1111/j.1475-4932.2012.00809.x
Jacobs, Jan P.A.M. and Simon van Norden (2016) “Why are initial estimates of productivity growth so unreliable?”, Journal of Macroeconomics, Volume 47, Part B, March 2016, Pages 200-213, ISSN 0164-0704, https://doi.org/10.1016/j.jmacro.2015.11.004.
Lazer, David, Ryan Kennedy, Gary King and Alessandro Vespignani (2014) “The Parable of Google Flu: Traps in Big Data Analysis” Science, Vol. 343, Issue 6176, pp. 1203-1205, https://doi.org/10.1126/science.1248506
This post written by Simon van Norden.
I forgot to include this reference:
Li, Xinyuan (2016) Nowcasting with Big Data: is Google useful in the Presence of other Information? London Business School mimeo
Simon van Norden: Thanks, reference added now.
I would imagine tools such as google trends suffer from feedback loop issues. The concept is fine, but once people start using the tool, it influences their actions. This feedback changes the observations from the tool itself, and is probably rather difficult to filter out. big data is an emerging field of importance, but it can suffer from the “measurement” problem, where a measurement impacts the future trajectory of the system. in addition, there is large variance in the quality of data scooped up in big data analytics-not all data is created equal. challenging problems. nice post.
A couple thoughts:
-Would researchers be able to look into more granular correlations based on metro areas? For example, observe the time-series for Google searches of “Chicago jobs” against Chicago job performance?
-Would researchers be able to run a regression of job searches per capita of U.S. counties against various jobs data series by county?
-Does age play a factor? For example, we know that different age groups are more likely to rely on the internet for job leads. In other words, maybe the model developed works better for predicting employment trends for younger age cohorts?
I have to believe that, at least internally, the people at Google are predicting all kinds of economic and social trends with the data they have. It still seems very intuitive that searches for “jobs” or “unemployment insurance” or “resume help” or something along those lines would track with unemployment claims or U6 fairly well.
baffling: Yup…Lazar et al. make just that point.
Mike v: You might want to check into the Google Correlate tool at https://www.google.com/trends/correlate, which lets you focus on searches from specific states, suggest your own search terms, and more. While the people at Google may be *trying* to predict all kinds of things with their data, it is clear that they have been *selling* the idea of predicting all kinds of things with their data.
Cool, thanks for the heads up!
the big data revolution reminds me of my earlier days in computer simulations, as the pc became bigger and more powerful. people became fooled by the large models we could construct, in exquisite detail, of some system under study. 1,000 degrees of freedom in the system quickly became 10 million degrees of freedom, and the analysts were convinced their models were better. garbage in = garbage out. same problems, different setting. today, i see computer science/bioinformatics folks streaming through gigabytes of genetic data-with absolutely no knowledge of biology! probably similar type of disconnect with the google flu problem. subject matter experts and data scientists usually do not work well together, but successful big data projects require both.
Prof. Hal Varian writes with an important correction: Choi and Varian (2012) are forecasting Initial Jobless Claims, not the Unemployment Rate.
Menzie, Simon: a big thanks. Interesting stuff.