Today we are fortunate to present a guest post written by Michele Ca’ Zorzi (ECB) and Michal Rubaszek (SGH Warsaw School of Economics). The views expressed are those of the authors and do not necessarily reflect those of the ECB.
We have just released a new ECB Working Paper entitled “Exchange rate forecasting on a napkin”. The title highlights our desire to go back to basics on the topic of exchange rate forecasting, after a work-intensive attempt to beat the random walk (RW) with sophisticated structural models (“Exchange rate forecasting with DSGE models,”).
Cheung et al. (2017) have recently reaffirmed the difficulties of finding models that consistently outperform the RW; however they also concluded that the Purchasing Power Parity (PPP) model performs fairly well. The starting point of our analysis is an observation that in-sample there are two important regularities in foreign exchange markets in advanced countries with flexible regimes. The first one is that real exchange rates are mean-reverting over the medium term, as implied by PPP theory. For the EUR-USD rate this is illustrated by the upper panel of Figure 1. The second regularity is that the whole adjustment takes place via the nominal exchange rate (NER, middle panel) and not via relative price indices (RPI, bottom panel). These results immediately prompt the question: why have researchers not exploited these robust features in the data to beat the RW?
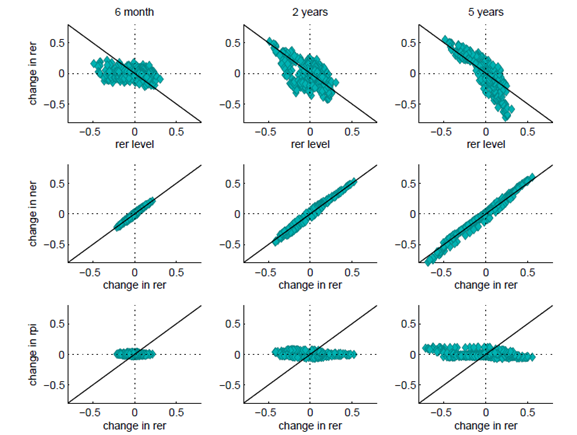
Figure 1: Exchange rate regularities for the euro dollar. Notes: Changes for a variable Y over horizon H are expressed as Δyt,H = yt-yt-H, where yt=log(Yt). The rer level is equal to the deviation of rert-H from the sample mean rer-bar. See also Eichenbaum et al. (2017).
In the paper we evaluate several competing models that should be able to exploit the two above regularities to forecast nominal bilateral exchange rates of ten currencies against the US dollar. The winner of the forecasting horse race is a half-life (HL) model, which just assumes that the real exchange rate gradually returns to its sample mean and that relative price indices play no role in this adjustment. The key advantage of this approach is its simplicity. It can be easily implemented using the following formula:

where Δnert+h,h = nert+h-nert is a percentage change in the nominal exchange rate over horizon h, rer-bar is the sample average and ρ is the pace of mean reversion. Consistently with the meta-analysis of Rogoff (1996), we assume that half of the adjustment in RER is achieved in 3 years. This means that, in the case of monthly data, ρ=0.981.
The approach is so simple that it can be implemented on a napkin in two steps. Step 1 consists in calculating the initial currency misalignment with an eyeball estimate of what is the distance between the real exchange rate and its sample mean. Step 2 consists in recalling that, according to the above formula, one tenth of required adjustment is achieved in the first six months, one fifth in one year, just over a third in two years and exactly half after 3 years.
In the paper we compare this simple approach to the RW, which serves as a benchmark, as well as to other models, in which the pace of mean reversion over horizon h is estimated with individual currency time series (direct forecast, DF model) or panel data (PDF model). The comparison of the forecasts is done using the Root Mean Squared Forecast Error (RMSFE), where the relative performance is tested with the Diebold-Mariano and Clark-West tests.
The results, which are presented in Table 1, show that the HL model beats overwhelmingly the RW at all horizons. Moreover, problems arise when attempting to carry out more sophisticated approaches, such as estimating the pace of mean reversion of the real exchange rate or forecasting relative inflation. Among the estimated approaches, in the paper we indicate that it strongly preferable to rely on direct rather than indirect forecasting methods. We also find that models estimated with panel data techniques (PDF) perform marginally better than those based on individual currency pairs (DF) but not enough to change the outcome. Even though both these models tend to beat the RW at horizons above 2 years, they tend to lose against the HL model, especially at shorter horizons.
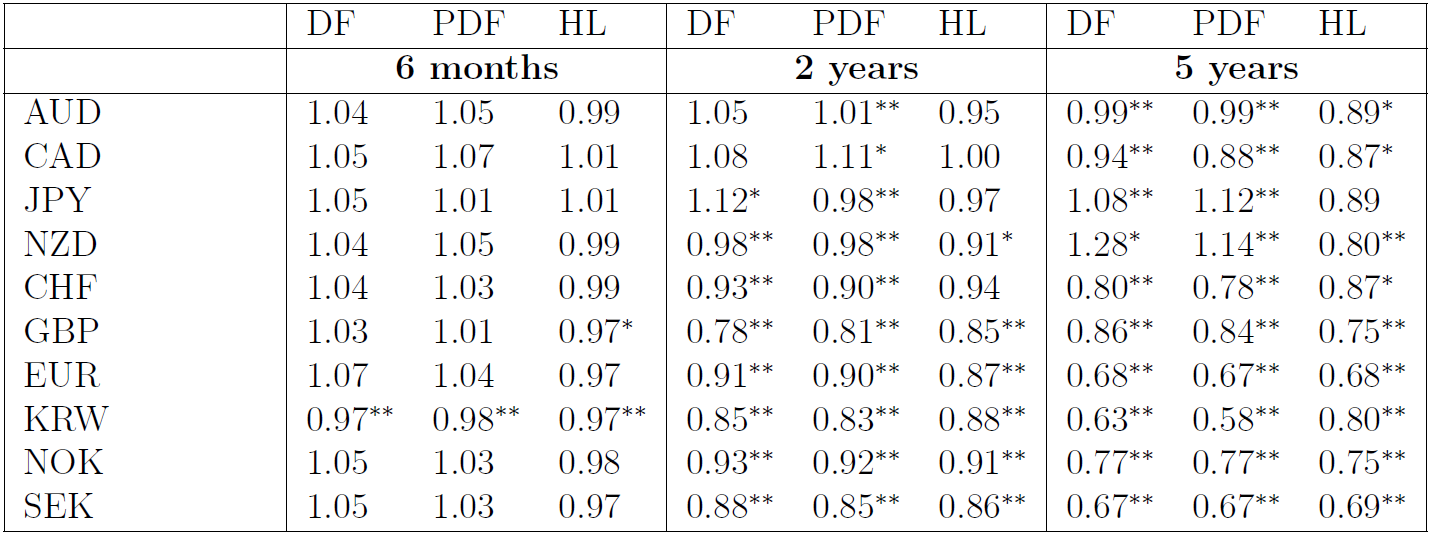
Table 1: RMSFE for the NER with respect to the RW. Notes: The table shows the ratio of RMSFE from a given model in comparison to the RMSFE from a RW. Asterisks ** and * denote the 1% and 5% significance levels of the one-sided Diebold-Mariano (HL model) or Clark-West (DF and PDF models) with the alternative that a given model performs better than the RW.
Our findings have bittersweet implications. On the negative side, estimated models encounter a second formidable competitor that, like the RW, bypasses the estimation error problem. On the positive side the HL model is much more acceptable than the RW from the perspective of economic theory. Our analysis helps one to reconcile the evidence from different strands of the literature. The key takeaways are at least fourfold. First, PPP holds for advanced countries. Second, the nominal exchange rate is the driving force of the adjustment. Third, estimation error is the reason for failure of why many models do not outperform the RW, particularly at short horizons and with indirect forecasting techniques. Finally, the RW is beaten by a calibrated HL PPP model in a very robust and consistent way across a multitude of currency pairs.
References
This post written by Michele Ca’ Zorzi and Michal Rubaszek.
Very interesting, but I have a quibble. I don’t believe they are using the Diebold-Mariano (DM) test in a way that Diebold would entirely approve. The DM test was intended to evaluate in-sample forecasts; it was not intended to evaluate out-of-sample models. Of course, the authors are hardly the first to use the DM test to evaluate models (note: in the discussion above they refer to “forecasts”, but on page 6 of their paper they refer to using the DM test to evaluate “models”). And I’m as guilty as anyone else when it comes to using the DM test to evaluate out-of-sample models, so I don’t want to throw too many stones. But it’s worth pointing out that Diebold himself, while feeling flattered, doesn’t entirely agree with using his test this way.
https://www.sas.upenn.edu/~fdiebold/papers/paper113/Diebold_DM%20Test.pdf
I think the point of the models is their predictive “power”. Do the models make a more accurate and/or closer prediction?? If they attain the desired results, who is going to really argue with that?? This isn’t Robert Plant stealing Willie Dixon lyrics. Or Elvis popularizing black music with a white face. Or Keith Richards repackaging Chuck Berry guitar chords with Mick jagger’s lips. This is the kind of stuff Aaron Swartz ended up being persecuted for. The information doesn’t do anyone any good if people want to sit around arguing how it gets used.
@ 2slugbaits
I mean a solid “NER” forecast (i.e. “the best possible” NER forecast) is the end goal, correct?? Or am I just weird in the head or something?? Ok, yeah, just answer the first question please.
Really interesting stuff.
One apparent advantage with the Half-Life model that the authors did not point out is just how consistently it beats the Random Walk model. Even though the PDF and DF models outperform it on average at the 5-year horizon, they sometimes do significantly worse at that period while HL always seems to outperform RW.
Surely this is worth mentioning? If I were a risk averse investor I would prefer Half-Life at all time horizons for that reason.
It seemed like to me the authors had made that pretty clear towards the last part of the explanation. But I’m not grasping all of this yet, so maybe I missed something.
Paul Krugman has suggested more than once that the field of economics (especially as it relates to career paths) has become overly-dominated by the DSGE models. Krugman seems to be saying that IS-LM encourages certain thought processes and theorizing by the average economist, which DSGE does not—DSGE is mainly “plugging in” numbers, sometimes with less thought or theorizing. My interpretation (paraphrasing) of Krugman’s thoughts is, he is FAR from saying DSGE should be “thrown away”. Krugman is only arguing it has become overly-dominant in journals and for Economics career path advancement.
If I have misinterpreted Mr. Krugman’s thoughts, I apologize, and Mr. Krugman (I suspect he visits Menzie’s “humble” blog from time-to-time) is very welcome to correct me or set it straight.
I want to say more about this guest post, by the two fine gentlemen above, as I do also want to make some comments about Mr. Thorbecke’s guest post. But I need more time to read and have the concepts soak into my brain, before I can type intelligently about them.
I’m not sure if this is a completely “up-to-date” version or “last revision” version, but here is a link to the last paper mentioned in the references:
http://faculty.wcas.northwestern.edu/~yona/research/EJRNovember242016.pdf
Not that I could actually fully comprehend it, but mainly to humor me, does anyone know where I can access the Mark and Sul 2012 paper?? I found a 2001 paper with similar terminology, but it seems dated a little. I would much prefer a FREE non-paywall version, but any link or hint on where I could find that would be great. Thanks ahead of time.
Nice to see the entry about this paper here. Not so long ago Mr. Rubaszek presented this research at the seminar in Warsaw. Fast and very simple method to use. Personally I find it very useful as another tool for judging possible foreign exchange rate movements. The horse race is on 😉
I would have wagered, due to his sharp mind, that he was Polish Jew, but I looked at a long list of surnames and Rubaszek is not on it.