Reader Steven Kopits writes:
The method of presentation depends on the data. If you work with the VMT data, you know there’s lots of chop, and the seasonally adjusted figures, well, may not accurately represent seasonal variation. That’s why Menzie’s graph looks like such spaghetti.
So how to present? You could do 3 mma over prior year 3 mma. Still too choppy. You could present annual totals or averages by calendar year, but you’ll miss turning points. You can do monthly changes, a la Menzie, and get garbage.
But one option is a rolling 12 month average. That eliminates the whole seasonality question and provides a nice, smooth graph. The downside is that it may be late to show an inflection point and, in the current case, may be distorted the data by the rise in VMT in 2021.
So you have to make decisions, and each of those involves some sort of compromise.
I think you’ll agree, Menzie’s graph is hardly legible, much less possible to understand. I have no idea why he felt a need to do it, because he already had a visual the last time we discussed the topic.
The only graph in the post being commented on is this one:
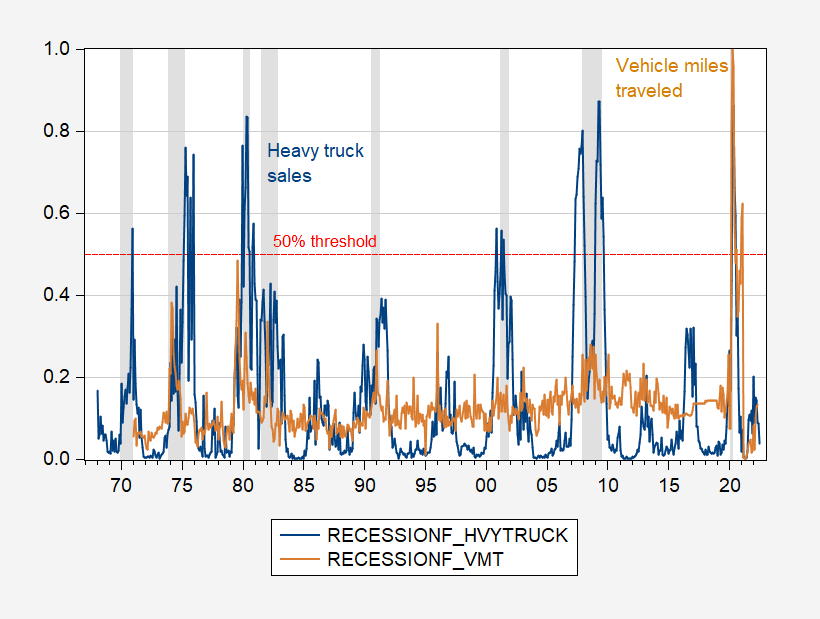
Figure 1: Recession probabilities using contemporaneous 12 month changes in heavy truck sales (blue), and in vehicle miles traveled (tan). 50% threshold dashed red line. NBER defined peak-to-trough recession dates shaded gray. Source: Author’s calculations.
Strangely, Mr. Kopits does not seem to realize — despite the note to Figure 1 — that this is a graph of estimated recession probabilities, and not the underlying vehicle miles traveled (VMT) series (and heavy truck sales).
Here is the 12 month (log) change in vehicle miles traveled, and change in the 12 month rolling averages Mr. Kopits says he prefers (for the 2000-2022 period).
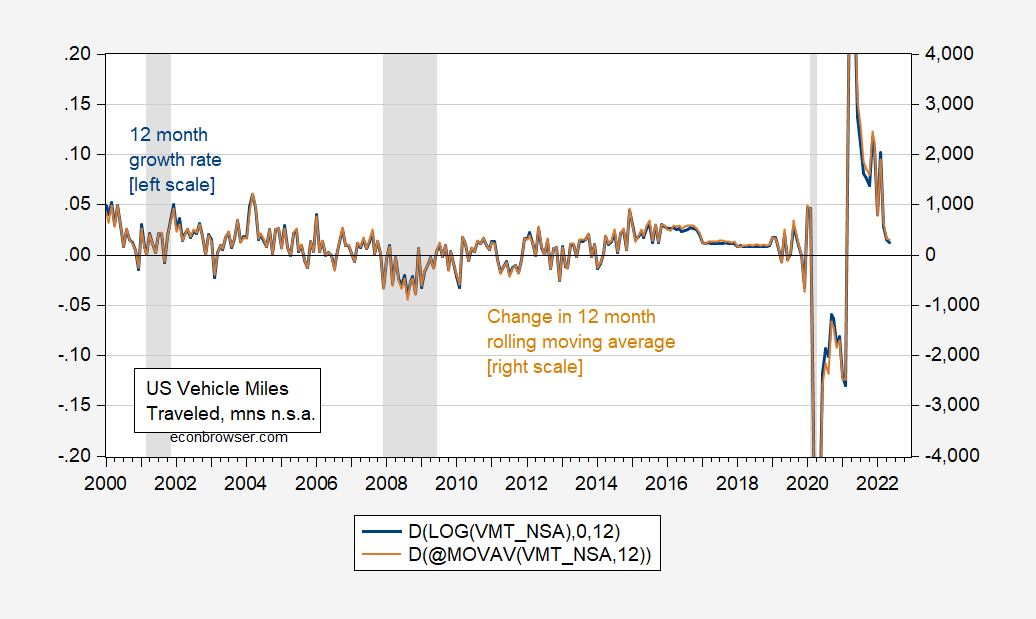
Figure 2: 12 month change in log vehicle miles traveled (blue, left scale), and change in 12 month moving average of vehicle miles traveled, in millions (tan, right scale), both n.s.a. NBER defined peak-to-trough recession dates shaded gray. Source: FHA via FRED.
The blue line is the data I used in the probit regression, the tan line is the one month change in Mr. Kopits’ preferred measure. The adjusted R2 of regressing one on the other is 0.99. In other words, had I used Mr. Kopits’ preferred measure, I would get the same implied recession probabilities.
I have tried to be comprehensive in the notes to the figures I provide (particularly ever since one reader accused me of manipulating the data), but sometimes I just wonder if it’s worth it, given the inability of certain individuals to read/comprehend.
Favorite blog post title of ALL TIME. I love it.
The presentations are invariably remarkably clear, and I consider that essential while always appreciating the efforts:
http://www.nytimes.com/2005/09/30/opinion/30greene.html
September, 1905
Einstein’s Equation
An object’s mass is its resistance to being accelerated (to having its speed increased). According to E = mc2, an object’s mass depends on its energy. This means that the faster an object goes, the harder one must push to increase its speed. (If an object’s “rest mass” – called m0 – is the resistance it has to being sped up from a resting position, then Einstein’s result can be written more explicitly as E = m0c2/ (1-v2/c2)½, so m = m0(1-v2/c2)-½, where v2 is the square of the object’s speed. As the formula shows, when the object’s speed approaches that of light, its mass grows infinitely large, which explains why, regardless of how hard it is pushed, it won’t exceed light speed.)
— Brian Greene
Professor Chinn,
I have a sense that those readers who like to replicate your work as a learning experience appreciate that you are “comprehensive in the notes to the figures” you provide. A lot of work on your part, so thanks.
I’m too lazy of a commenter to do that but I still heartily agree. And I may do so in the future! Thank you for pointing this out AS. And thank you to MC for thorough (and also entertaining) data posts.
I’m so glad you said this “AS”. I think there is a “silent” group out there, similar to the folks who read the blog but maybe don’t comment. I mean on the rare times I have attempted to use “R” program and do some of these regressions and OLS etc. I was incredibly grateful that Menzie had put some of that data up. And sometimes you can “sorta kinda” reverse engineer those printouts and different things it really helps to save time to know if you are doing things right, or even if you’re wrong to see if you’re answer/numbers are “in the ball park”. I think “AS” knows this feeling as he has enquired when he got a solution very near to Menzie’s but were just slightly off and wanted to know why.
Professor Chinn I have tried to remember to thank you for doing these things, and I think commenters should show appreciation~~but just because commenters/readers sometimes forget to say “thank you” please don’t assume the extra effort on footnotes and details is not appreciated. There are people out here who DO appreciate that.
“I mean on the rare times I have attempted to use “R” program and do some of these regressions and OLS etc.”
So cool Moses! R’s a bit of a learning curve (especially if you don’t have the econometrics down already – we often use Stata to teach instead as the syntax and data structures are just simpler) but it’s always free so you can just keep learning indefinitely. It’s very rewarding. Do you use R Studio? It’s a (free) bit of software that runs R that can help you with the coding (pop-ups and pull-down menus and built-in documentation and stuff like that). Recommended for any R users.
A modern econometrics intro text that I like is Stock and Watson. If you’re more advanced than that, go with AS’s fav, Wooldridge. I wouldn’t just google around for econometrics answers – it gets very confusing very quickly. They both throw in some basic time-series stuff. (HINT HINT YOU CAN GET FREE PDFS OF TEXTBOOKS ON LIBRARY GENESIS HINT HINT NO I’M NOT ADVOCATING PIRACY YOU ARE)
Menzie, would you recommend a good intro time series textbook? Hell, I could use one too.
Andrew,
As an old CPA and business exec., I defer to Professor Chinn on recommendations.
Below are few texts that I think are very good and useful for self-study.
1. “Forecasting, Time Series and Regression”, Bowerman, O’Connell, Koehler, 4th edition, Cengage, 2005. There may be a later edition. Great chapter on intervention models. More time series than econometrics.
2. “Forecasting for Economics and Business”, Gloria Gonzales-Rivera, Pearson, 2013. More time series than econometrics.
3. ‘Principles of Econometrics, 4th edition”, Hill, Griffiths, Lim, Wiley, 2011. There may be a newer edition.
4. “Introductory Econometrics A Modern Approach, 5th edition”, Cengage, 2013. There may be a newer edition.
5. “Basic Econometrics 4th edition”, Gujarati, McGraw-Hill, 2003. There may be a newer edition.
AS: Good recommendations I think. Myself, I use Stock and Watson’s Econometrics. In the old days, Pindyck and Rubinfeld. For advanced, use of course James Hamilton, Time Series Analysis (!). I truly wish CoRev would try his hand at the latter.
Professor Chinn showing his near limitless faith in humanity thinking CoRev will ever put a single fingerprint on an Econometrics text. You gotta like that kinda faith. That’s why some people become teachers/professors~~that belief in people taking themselves off the dungheap.
Thank you to both AS and MC! Most of these texts I don’t know and sound great. Am making a Sticky Note now.
I use the R Studio but lately the versions aren’t matching up and it won’t do dotplots, so I don’t know how much I can get done when R studio won’t do dotplots until I figure out what the problem is with the damned versions. It’s incredibly aggravating, And yes I have also download the “X” thinguh-which-whatly that you need to make it work but my R and R studio seem to be arguing right now, that is the stuff the drives me nuts because it kills my progress,
I’m gonna make another run at it though, maybe this winter, And Andrew I will look into your “creative” library ideas. I know what you mean Andrew, you’re totally not into pirate novels, but you “read Melville” sometimes, am I right?? Yeah, I “read Melville” sometimes too. We are just Pawboys trying to keep up in the world–no sin in that friend.. If there was sin in that, half my Asian classmates in college would be sitting in prison now for going to the copy shop with one text to make 5 zillion Xeroxes.
I’m going to just admit here that I haven’t had R or R Studio installed in like 2 years, so I am of limited use here. I didn’t think R Studio would have a problem with different versions of R though. Maybe the dependencies have changed for some reason? The errors should tell you something.
(To save myself dependency headaches, in my scripts I often keep the bits of code that download/install required dependencies even if the packages are already installed on my system. Saves me the trouble if I have to move to a different computer, or if I’m giving the code to anyone else.)
“Reading Melville” is sometimes very helpful for getting stuff that’s out of print and not in Google Books. But since I am not as poor as I used to be, and since I know some authors – including textbook authors – who resent how bad the publishing market is, I try to buy when I can, especially if the author is alive! Usually digital.
https://english.news.cn/20220808/8849c159ec624497945dff85338b23f5/c.html
August 8, 2022
China’s new energy sector moves into high gear amid pursuit for carbon goals
BEIJING — As construction of large-scale wind and photovoltaic power bases accelerates, China’s new energy sector is expected to have greater growth potential this year amid efforts to achieve “dual carbon” goals.
In Urumqi, capital of northwest China’s Xinjiang Uygur Autonomous Region, the construction of a wind power and photovoltaic base by China Huadian Corporation with a total installed capacity of 1 million kilowatts is progressing in full swing.
The project, which is among the first batch of large-scale wind and photovoltaic power bases greenlighted by the government, is expected to generate 2.5 billion kilowatt-hours of green electricity while saving consumption of 830,000 tonnes of standard coal and reducing carbon emissions of 2.1 million tonnes after completion.
All of the initial batches of such projects have thus far broken ground. The list of the second batch, which includes bases to be built in Inner Mongolia, Ningxia, Xinjiang, Qinghai and Gansu, has been released.
CONSIDERABLE ROOM FOR GROWTH
Experts believe that the promotion of new energy bases will significantly spur the development of the new energy industry.
In the first half of 2022, China’s installed capacity of wind and photovoltaic power added 12.94 million kilowatts and 30.88 million kilowatts, accounting for 18.7 percent and 44.7 percent of total new capacity, respectively, data from the National Energy Administration showed.
Driven by the country’s “dual carbon” goals, the new energy sector has become one of the few industries that features a high utilization rate without generating excess capacity, said Jiang Debin, an expert with the China Electricity Council.
Su Xinyi, an analyst with China Electric Power Planning & Engineering Institute, noted that the new energy sector will continue fast expansion in the second half.
China’s newly installed capacity of wind and photovoltaic power for the entire year is expected to exceed 100 million kilowatts, while the consumption of power produced by the two energy sources is estimated to reach over 12.2 percent of total power consumption, Su said.
EFFICIENT UTILIZATION ….
OK CoRev is nothing more than a barking dog who chasing his tail all day. Princeton Steve on the other hand routinely complains about well presented graphs and data as he has his own agenda – manipulate the data so the folks on Fox and Friends will invite him on their show.
I know – it is tiring but this is what happens when trolls are allowed on the internet.
With all the weird theory and manipulations of data to support his weird theories, I have to ask why the Usual Suspects do not pester John Cochrane over at his blog. Oh wait they share his right wing agenda. And to Cochrane’s credit – he replies to troll comments with a vengance.
Long overdue:
https://www.tampabay.com/news/florida-politics/2022/08/08/trump-says-fbi-executes-search-warrant-at-mar-a-lago/
Trump says FBI executes search warrant at Mar-a-Lago home
Trump: “They even broke into my safe.”
I’m guessing the keypad code was 1234.
@ joseph
5-star comment.
And no water pressure for his toilet. All jammed up with White House documents because no flush power. Next question is did they find ketchup on the walls and ceramic dishes broken on the floor??~~or does the orange ape only act like a 6 year old when White House staff do the clean-up. Maybe Mark Meadows can walk behind him around Mar-a-lago with one of those hotel maid carts.
That isn’t just a joke. Trump’s standard stump speech given hundreds of times always includes a five-minute rant about how Democrat regulators have reduced the water pressure of toilets so he has to flush two or three times. Now you know why. Democrats are crime stoppers.
You just don’t mess with the national archives – they WILL get you.
It is my understanding that they were looking for the second love letter from Kim Jong-un. The one where he suggested that they each pack a couple of nukes and elope to a volcanic island in the middle of the pacific.
Ivan, ah, the attack of the librarians is so dangerous. Weaponizing the Govt, especially NARA is just indicative of desperation and fear of Trump.
CoRev: Boy, glad you were never around classified documents…
Are you sure he wasn’t? After all – CoRev began his career working as one of those Dirty Tricks people that assisted Richard Nixon.
What does this have to do with soy bean prices?
“In Urumqi, capital of northwest China’s Xinjiang Uygur Autonomous Region, the construction of a wind power and photovoltaic base by China Huadian Corporation with a total installed capacity of 1 million kilowatts is progressing in full swing.”
Which Uigur concentration camps does this power, you think?
China has decided to play into the fear that it could dump its Treasury holdings:
https://www.globaltimes.cn/page/202208/1272269.shtml
The article which mentions using Treasuries as a weapon is a sophomoric hit piece aimed at Nancy Pelosi. That’s not a surprise – Xi has his panties in a twist over Pelosi’s Taiwan visit. This, however, the first time I’ve seen a mouthpiece for China’s government indulge in this threat. The clearest implication of this threat is that the twist in Xi’s panties is really bad, more than trade sanctions or mention of human rights violations.
Whether the threat is serious is another matter. China’s long-standing preference for an even keel over high drama suggests this is just a momentary emotional lapse of judgement. If, however, Xi intends to employ violence to satisfy his hegemonic urges, then China’s Treasury holdings would of course become available as a weapon. So maybe China’s use, or not, of financial tools for geopolitical gain will be a useful barometer of Xi’s willingness to kill in order to please his ego.
Huh, interesting. Pelosi really did get under their skin. It’s important for all of us to remember that the big change is in Beijing, not DC (though the US position on Taiwan has clearly shifted IN RESPONSE to Beijing’s growing belligerence).
Of course this is little better than Putin threatening to cut off Europe from gas. More of a threatened own-goal than anything. Why would CN want to massively boost the CNY/USD exchange rate? And don’t they know how deep the market is for US Treasuries?
I think what you are seeing from Kopits is an attitude problem, rather than an absence of intellectual capacity. I have two reasons for this view. First, understanding your presentation isn’t that hard; it doesn’t take a whole bunch of extra smarts to grasp your presentation, but Kopits regularly grouses about having difficulty. Something other than simply lack of capacity seems to be at work. The second reason, the one which identifies attitude as the problem – not that it needs explaining – is Kopits routine demonstration of cock-sureness when he is demonstrably wrong. (Cue 60s pop music…) He knows what he thinks before he looks at the evidence. In this case, the evidence is your presentation.
Why has Kopits chosen this particular hill to die on? I can only speculate, and I will. Kopits is the object of a lot of giggles from the gallery he’s in comments because of his pose as “the all-knowing consultant”. Poor clients! Kopits has clients? So what does he do in response? He pretends the highly credentialed, widely published, U.S.-president-advising University professor is in need of some tips on writing blog posts from his illustrious self. Kopits poses, as Kopits is wont to do.
When Dunnng and Kruger get together for drinks, they talk about guys like Kopits.
Rather, a(nother) short note on Menzie’s ego.
Econned,
You think Steven’s comments were useful or even reasonable on this? Are you in with him when he whines about Menzie using log scales as well?
“Barkley Rosser”,
Here’s what I am… I’m regularly disappointed in how poorly you engage in discussion when you routinely utilize such elementary fallacies. And you expect readers to believe you’re actually “Barkley Rosser”. You’re so incredibly narrow minded and argumentative that you’re unable to reconcile that Person A could criticize Person B’s attempt to sh*t on Person C’s comments and it not be at all related to Person A’s agreement/disagreement with Person C’s words. Here’s the thing, “Steven’s comments” sure as sh*t aren’t worthy of this over-the-top blog post – doesn’t matter if I agree or disagree with them. I don’t think in the same dogmatic fashion that you prefer. So to answer your first question, my reply is an obvious “no”. To answer your second question, that isn’t worth the ?dozens? of blog posts Menzie pens about that topic either. Menzie has an ugly ego problem and anyone with the slightest objective view can easily see it.
I note quite a bit of jealousy in these comments. Prof Chinn has had a quite successful career. Since econned has not had similar success, he attempts to tear down a more decorated colleague. Professional jealousy is sad.
HE’S INCREDIBLY NARROW MINDED?
YOu’re seriously commenting about someone with an ego problem?
The objectivity of others here is in question?
Please, physician, heal thyself.
Econned,
Oh, you are seriously losing it. What is with this nonsense about me not being me because I asked if you supported Steven’s in fact seriously stupid remarks on this stuff. Hey, Econned, are you not aware that I am someone who on many occasions and matters is the only person here defending Steven at times? Have not seen you stepping in to help out when he actually says some not totally unreasonable things and various people here are going after him tooth and gong, and sometimes after me as well. Do not remember you supporting me when I was reasonably defending him.
No, you just completely lose it on this remark.
Look, bozo, I personally know Menzie. He is not an egomaniac. He is a mild-mannered teacher. You are a disgusting creep, one of the worst participants on this list, and your obsession with Menzie’s supposed overblown ego is just sick, as well as stupid and disgusting. You are way wrong. I suggest you never ever post here one of your worthless diatribes about his ego. You are only barely above CoRev as being the worst troll here.
“Barkley Rosser”,
1) You miss the target. Yet again. You fail to read and/or comprehend. That’s why I don’t think you’re “Barkley Rosser” that and, as stated in the comment above, your constant misuse of logic in your replies. Please. Keep. Up.
2) its you who is losing it on your your remarks because you defending Steven (or not) “at times” is wholly irrelevant
3) you name calling is another example of your failing at dialogue and resorting to logical fallacies
4) you suggesting that I “never ever post here” is childish and hilarious – very telling of your demeanor and
5) you’ve commented nothing of substance, yet again, to the topic I’ve brought up. So, no, I do not believe you’re “Barkley Rosser” as I’ve stated elsewhere on this blog
“Econned,”
You are degenerating right before our eyes.
You claim I’ve “commented nothing of substance, yet again, to the topic I’ve brought up.”
The topic you brought up was Menzie’s ego, your obsessive claims he is some kind of egomaniac. You are wrong.
I made a very substantive comment. I know him. You do not. He is a mild-mannered teacher, the exact opposite of an egomaniac.
The egomaniac here is you, “Econned,” but unlike Menzie you have yet to provide a shred of evidence to support the idea that there is any remotely credible basis for your egomania.
Oh, “Econned,” and your weird effort to somehow claim that I am not me is just hilarious. It somehow suggests that you actually respect and take me seriously, so now I am being bad and not living up to myself that you so profoundly respect.
But anybody who has followed things here know that you have never expressed any such respect for me. Heck, you were joining Moses Herzog in declaring me to be senile. I am not so senile as to have forgotten that, boy.
“Barkley Rosser”,
It isn’t relevant that you know Menzie personally. Menzie can be an egomaniac on his blog but that doesn’t mean Menzie is an egomaniac around you or in other settings (let’s ignore the fact that your anecdotes are only that). Such continual lack of basic logic on your part leads me to conclude you are not the academic Barkley Rosser. Let me be clearer for you – “Barkley Rosser” on Econbrowser is an entity who regularly comments with failed and/or nonexistent logic while also engaging in elementary logical fallacies in discussions. The academic Barkley Rosser is not known to do such in their published research. So, maybe you are the academic Barkley Rosser and your online persona differs from your persona in academia. Maybe in suggesting you aren’t the “real” Barkley Rosser I was just being hopeful for the sake of your profession, your peers, your colleagues, your mentors, your mentees, your family, and your own integrity.
Now remember, that. Boy.
Econned, why do you post under different names to defend your econned comments?
Another waste of space. Find another blog to infest.
Rather a profound note by Menzie Chinn, on what teaching needs to be about.
https://news.cgtn.com/news/2022-08-07/Diplomats-from-30-Islamic-countries-visit-Xinjiang-1ciXFznlizm/index.html
August 7, 2022
Diplomats from 30 Islamic countries visit Xinjiang
The diplomats from the countries including Algeria, Saudi Arabia, Iraq, Yemen and Pakistan visited the regional capital city of Urumqi, Kashgar Prefecture and Aksu Prefecture, learning about the region’s economic and social development.
They witnessed Xinjiang’s achievements in social stability, economic development, the improvement of people’s livelihoods, religious harmony and cultural prosperity, expressing their hopes that exchanges and cooperation with the region would be deepened.
“The fruit here is so sweet, just like the life of the people here,” said Hassane Rabehi, Algerian ambassador to China, adding that during this visit, he got to know the real situation of Xinjiang, where the rights of people of all ethnic groups are well protected.
Hassane Rabehi said that Algeria hopes to conduct more cooperation with Xinjiang on infrastructure construction, modern agricultural development, education and scientific research.
Abdulrahman Ahmad H. Alharbi, ambassador of Saudi Arabia to China, said that Xinjiang’s achievements are remarkable and its ties with the world are growing closer.
According to the ambassador, Saudi Arabia is willing to continue to strengthen cooperation with Xinjiang, make good use of the advantages of both sides, and invest more in technology, knowledge and other fields.
Bruneian ambassador to China Pehin Dato Rahmani said that after years of effort, Xinjiang has made remarkable achievements in development. People of all ethnic groups here are living together in harmony and enjoying the freedom of religious belief. People’s livelihoods have also been improved….
““The fruit here is so sweet, just like the life of the people here,” said Hassane Rabehi, Algerian ambassador to China, adding that during this visit, he got to know the real situation of Xinjiang, where the rights of people of all ethnic groups are well protected.”
Holy Jesus, you are all about papering over massive-scale human rights abuses, aren’t you?
https://english.news.cn/20220728/e6dfdc6ad28f4de7a00804a605eb1757/c.html
July 28, 2022
Teachers’ home visits tell growth stories of Xinjiang students
* China has been sending students from Xinjiang to study in vocational schools in east and central provinces and municipalities since 2011 to promote the training of talent from all ethnic groups in Xinjiang.
* Teachers from the Changxing Vocational and Technical Education Center School in east China’s Zhejiang Province pay home visits, some 5,000 kilometers away in Xinjiang, every year to address their students’ difficulties.
* A total of 543 Xinjiang students have graduated from the school since 2011, and become police, teachers, entrepreneurs, college students, soldiers and workers.
URUMQI/HANGZHOU — After finishing the school year in east China’s Zhejiang Province in early June, over 200 students from Xinjiang Uygur Autonomous Region some 5,000 kilometers away embarked on their homeward journeys.
More than 20 teachers from the Changxing Vocational and Technical Education Center School also boarded the train. They were not only chaperoning the trip, but were also planning to visit their students’ homes.
Gu Hailin, vice headmaster of the school, has been accompanying students on the same trip for more than a decade. Over the years, Gu has left footprints across both sides of the Tianshan Mountains, as the students hail from every part of Xinjiang.
“We hope to address the students’ difficulties and their parents’ concerns to the extent of our abilities during those home visits,” Gu said.
Merdang Nurmemet from the SOS Children’s Village in Urumqi was among the 81 Xinjiang students to graduate from the school in 2022.
“After the high school entrance examination, the teachers in the children’s village suggested that I apply to a secondary vocational school, so I would not have to worry about tuition and living expenses,” said Merdang, who was orphaned at an early age.
The central government and the county government of Changxing respectively allocate 10,000 yuan (about 1,483 U.S. dollars) and 7,500 yuan per student every year. Students from Xinjiang not only enjoy free tuition, accommodation, food and school uniforms, but also receive a government grant of 200 yuan per month.
OUTSTANDING GRADUATES
Statistics from the Changxing vocational school show that 543 Xinjiang students have graduated since 2011, among whom 38 became police, five became teachers, 15 started businesses, 98 were admitted to colleges, and 16 joined the army. The majority of other Xinjiang students began working at various enterprises.
When revisiting Hayisarjan Tahir in Xinjiang’s Hui Autonomous Prefecture of Changji, Gu proudly proclaimed his former student to be “one of the school’s most outstanding graduates.” …
Any students from the concentration camps joining these programs?
I mean, did you forget about those?
Interestingly and importantly, just this June there was 23 million domestic and foreign tourist trips made to Xinjiang. What with the new airport, new high speed rail line, new international freight rail line, new cross desert highway, new around desert highway, there will be ever so many more travels to and from Xinjiang. Xinjiang, after all, is a remarkably attractive year-round tourist region:
https://english.news.cn/20220705/ac8aeb6a90a04615bb21319ef27d9715/c.html
July 5, 2022
Booming tourism tells of a flourishing, stable, open Xinjiang
https://english.news.cn/20220616/e2a12a3d9f4d46f7be92cc16e676032a/c.html
June 16, 2022
China inaugurates world’s first desert rail loop in Xinjiang
* The 2,712-km loop, encircling the Taklimakan, China’s largest desert, and linking major cities including Aksu, Kashgar, Hotan and Korla along its route, is expected to put the development of Xinjiang, especially its southern part, on a faster track.
* The opening of the Hotan-Ruoqiang railroad has brought an end to the unavailability of train service in five counties and certain towns in southern Xinjiang and will shorten the travel time for locals.
* The new line will facilitate the transportation and logistics of Xinjiang specialties including cotton, walnuts, red dates, and minerals. It is also of great significance to driving resource development, safeguarding ethnic unity, consolidating frontier defense, and boosting rural vitalization along the route.
URUMQI — With the very first train roaring northeastward from Hotan, northwest China’s Xinjiang Uygur Autonomous Region, the Hotan-Ruoqiang railway was formally put into operation Thursday. It also marks the inauguration of the world’s first desert rail loop line….
Interestingly and importantly,
Egypt, Saudi Arabia and United Arab Emirates are negotiating joining the BRICS nations, which of course include China;
Among infrastructure projects in Egypt, China is working on building a new Cairo, a new Egyptian capital;
As for the nations of the Shanghai Cooperation Organization, which include China, nation after nation of the SCO is predominantly Muslim.
https://news.cgtn.com/news/2022-08-07/Diplomats-from-30-Islamic-countries-visit-Xinjiang-1ciXFznlizm/index.html
August 7, 2022
Diplomats from 30 Islamic countries visit Xinjiang
Diplomats from 30 Islamic countries visited northwest China’s Xinjiang Uygur Autonomous Region from August 1 to 4, at the invitation of the Chinese Foreign Ministry….
“The fruit here is so sweet, just like the life of the people here,” said Hassane Rabehi, Algerian ambassador to China, adding that during this visit, he got to know the real situation of Xinjiang, where the rights of people of all ethnic groups are well protected.
Hassane Rabehi said that Algeria hopes to conduct more cooperation with Xinjiang on infrastructure construction, modern agricultural development, education and scientific research….
more propaganda from a ccp website.
Mr. Kopits does not seem to realize — despite the note to Figure 1 — that this is a graph of estimated recession probabilities,
If that’s the case, then it’s not so much an idiotic comment as an ignorant comment. My hunch is that Steven Kopits wasn’t familiar with probit models, but only he knows for sure.
2slugbaits,
I think you are correct. Below is my “two cents” to perhaps help Steve.
The probit model is a binary model that forecasts a cumulative standard normal distribution value. As Jeffery M. Wooldridge says, “In most applications of binary response models, the primary goal is to explain the effects of the xj on the response probability, P(y= 1|x).” In the heavy truck model, recession is indicated by a binary variable such as FRED series USRECM, which is 0 or1. EViews uses an iterative maximum likelihood method to “solve” the model and can be used to forecast the probability or Z score associated with the Y/Y change in heavy truck sales. If one selects the Z score value forecast, then the EXCEL function Norm.S.Dist can be used to convert the Z score to a cumulative probability value for each “Y” value output. Using a statistics book showing the value of the cumulative normal standard distribution from negative infinity to the Z score, we can compute the probability for the July output of the probit model for the heavy truck example. I am showing a Z score of -1.86 for the July 2022 output from the model. To convert this Z score to a probability, I notice from the text that a Z value of -1.86 is equal to a cumulative probability of about 3.1%. Using EViews to forecast the probability the value is the same 3.1%.
Refinement of the about is welcomed.
Very good natured of you, AS, and a helpful post.
And yes, Wooldridge’s textbooks are very helpful to anyone learning or doing econometrics. For intro courses, we use the intro textbook by Stock and Watson.
It’s also totally true that you can do a lot even in Excel. And many powerful statistical software packages are free. Anyone with some basis in stats and probability can learn and do econometrics and data science. You don’t even need a powerful computer if you’re using relatively small datasets.
If, however, — intends to employ violence to satisfy his hegemonic urges, then ——- Treasury holdings would of course become available as a weapon. So maybe ——- use, or not, of financial tools for geopolitical gain will be a useful barometer of —- willingness to kill in order to please his ego.
[ This is slander, and violently expressed slander at that. What shame. ]
Xi has sent his military to intimidate Taiwan. That amounts to Xi threatening to kill Taiwanese in order to enforce his own political wishes. That’s not slander, you mewling twit. It’s a simple acknowledgement of reality.
I’m “feminizing slander”? Oh, my! You justify racially-based mass murder for and living and “feminizing slander” is my crime? You’ve sold out, you little cur.
— has his panties in a twist…. This, however, the first time I’ve seen a mouthpiece for ——- government indulge in this threat. The clearest implication of this threat is that the twist in —- panties is really bad, more than trade sanctions or mention of human rights violations.
[ Notice the evident need to feminize slander. ]
and yet ltr is permitted to make unsubstantiated statements of slander when calling others racist?. that is right, ltr does not believe rules apply evenly to all.
I mean, you give us post after post whitewashing the imprisonment of hundreds of thousands of ethnic minorities. Every day. Like it’s your job. That’s disgusting.
Your presence in these comments would be greatly valued if you didn’t so gleefully serve as the mouthpiece for such a hideous regime. Your other posts are great. What is the point of carrying water for Xi Jinping (unless it really is your job)?
Steven’s comment is supported in the need to have another explanation in the guise of a mocking article. He also referenced a 3+ years old article: ” This entry was posted on April 12, 2019 by Menzie Chinn. ” How many times has he referenced and/or written about this specific question? It appears to be too many times for a secure and self assured PHD.
Econned mentions an ego problem, which is evident in the number of mocking and retributional articles written aimed at those who question him.
you guys do not question prof chinn. you pontificate and assert without valid proof. in addition, you never learn when he responds. that is deserving of a public humiliation every know and then. I would ban many of your comments on the grounds of idiocy.
I’m surprised CoRev was even able to write this babble given he chases his own tail all day long.
First, I really do appreciate the data being presented in the way it was. Some data is choppy, and attempt to smooth it obscure the picture rather than give clarity. I spend a lot of time thinking about ways to present data such that it can be digested by the intended target audience. This is a fairly technical blog, so I would expect most readers to be somewhat technical and thus able to quickly comprehend a choppy graph. If the target audience was intended to be casual readers who want to grasp a concept at a glance (without really wanting detail), I might have considered presenting that graph as upper/lower confidence intervals (Perhaps 12, 24 or 36 month rolling band if it is trending), then showing the outliers as points as well as the current measure as a point. This takes the choppy look out of the ‘normal’ months (Since those details aren’t on the graph) and the outliers are easy to spot. But again, that would be for a non-technical audience. (Perhaps your readership has grown to the point that most readers pretend to be technical, but are in fact, just casual lurkers, IDK)
[ In my best Brian Sewell-like British accent ] Casual Lurkers?!?!?!?! Egads Sir!!!! Take back your balderdash this instant, or I shall be forced to ring up the codswallop police!!!!
My suspicion is that much of the ideologically-inspired look push-back in comments is aimed at casual lurkers. Ideologues can’t reasonably expect those with a strong foundation in economics to be fooled by their antics. They may, however, hope to raise doubts among those who have a less solid grasp of economics. That’s what “fake science” propaganda employed by the tobacco and fossil fuel industries was designed to do.
I don’t understand those commenters who have an issue with prof chinn on this issue. Steven kopits has made these types of inaccurate statements many times. he has been corrected many times. and yet still repeats the same mistakes. why should commenters stay silent and pretend these statements by Steven have credibility? this is damning evidence of somebodies analytical abilities. the credible person would remain silent, rather than double down. or at least admit to the mistake. same goes for his defenders.
And CoRev while chasing his own tail starts barking loudly in some incoherent “defense” of Stevie boy. OK it is not as incoherent and insane as CoRev’s weird attempts to defend Bruce Hall’s stupidity. Idiotic comments could be done using almost every piece of nonsense from Bruce Hall and his mad barking dog.
This short note on idiotic comments is sure to solicit long idiotic responses. SAD
Not that many. It’s been pretty good. Unless you could our requisite CCP posts, which appear with a probability of 1 in these here parts.
My theory is it’s the summer heat, and it makes a lot of people more ill-tempered. You see more “road rage” around this time of year, etc. Another 6 weeks I think people will start to cool down and calm down. I really kinda hate the summer, so I know what I’m talking about.