In a new paper, Ryan LeCloux (Legislative Reference Bureau) and I discuss the challenges to assessing the economic outlook at the state level. We examine the various indicators available to track macroeconomic indicators at the higher than annual frequency. We find that quarterly GDP at the state level is correlated with different macroeconomic indicators for different states. Hence, tracking the economic activity of each state accurately might require focus on different variables.
The Coherence between GDP and Other Macro Aggregates
Contrary to some speculation, the Philadelphia Fed’s coincident index is a fairly effective indicator of GDP. In 72% of the cases, the correlation of log first differences is positive and statistically significantly so. Next consider a sensitivity coefficient obtained from the following specification:
Δyt = α + βΔxt + εt
Where y ≡ ln(Y), so Δy is the essentially the growth rate on a quarterly basis of real GDP, while Δx is the growth rate of either real income, nonfarm payroll employment, civilian employment or the coincident index. The results of this regression are shown in Table 2 from the paper.
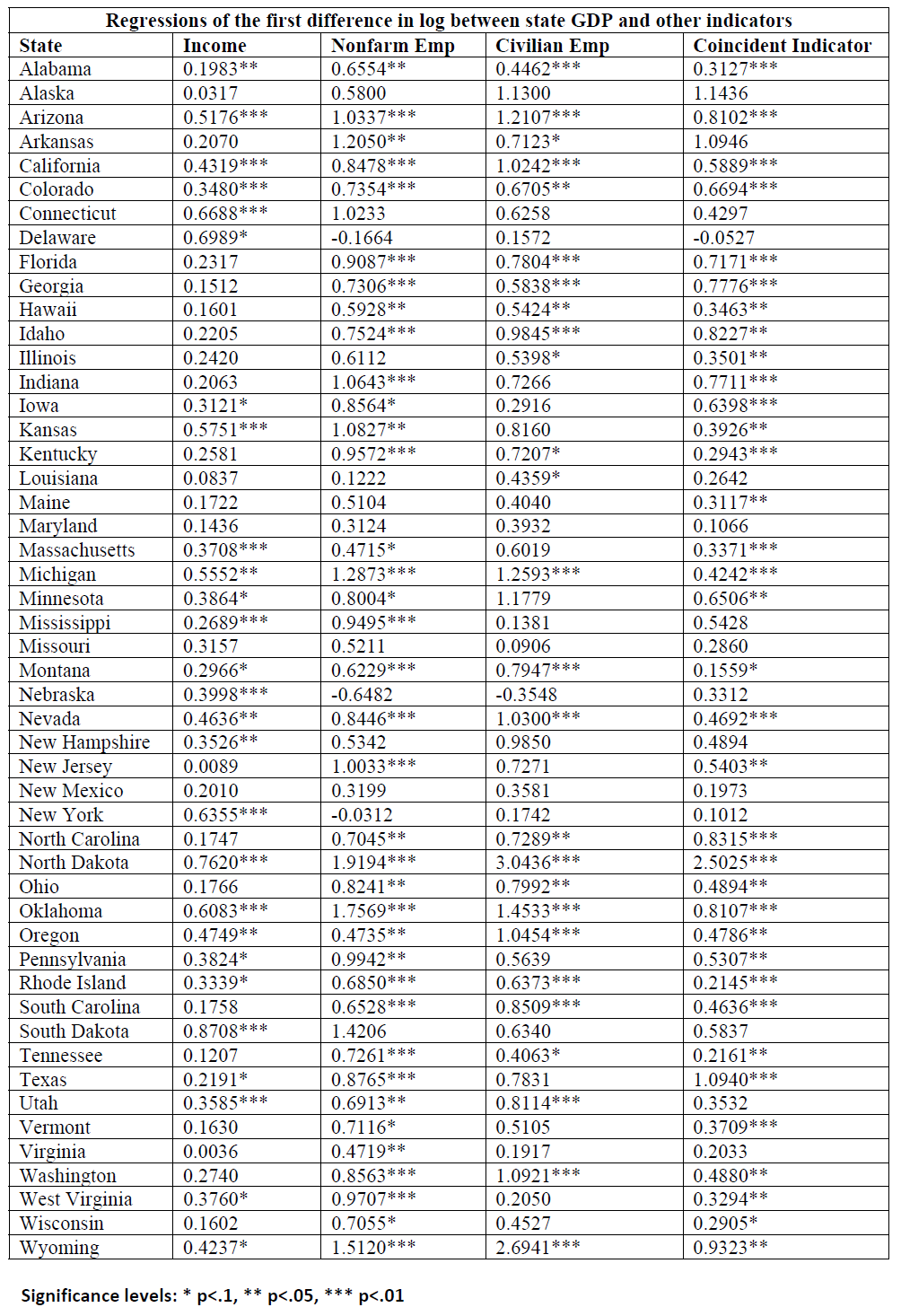
Table 2 from Chinn-LeCloux (2018).
The sensitivity of GDP growth to coincident index growth (the estimated β coefficient) varies from 0.29 (Wisconsin) to 2.5 (North Dakota), in the cases where the coefficient estimates are significantly different from zero. The latter is somewhat of an outlier; the next highest sensitivities are 1.095 (Akransas) and 1.094 (Texas). A geographic depiction of the sensitivities is shown in Figure 9 from the paper.
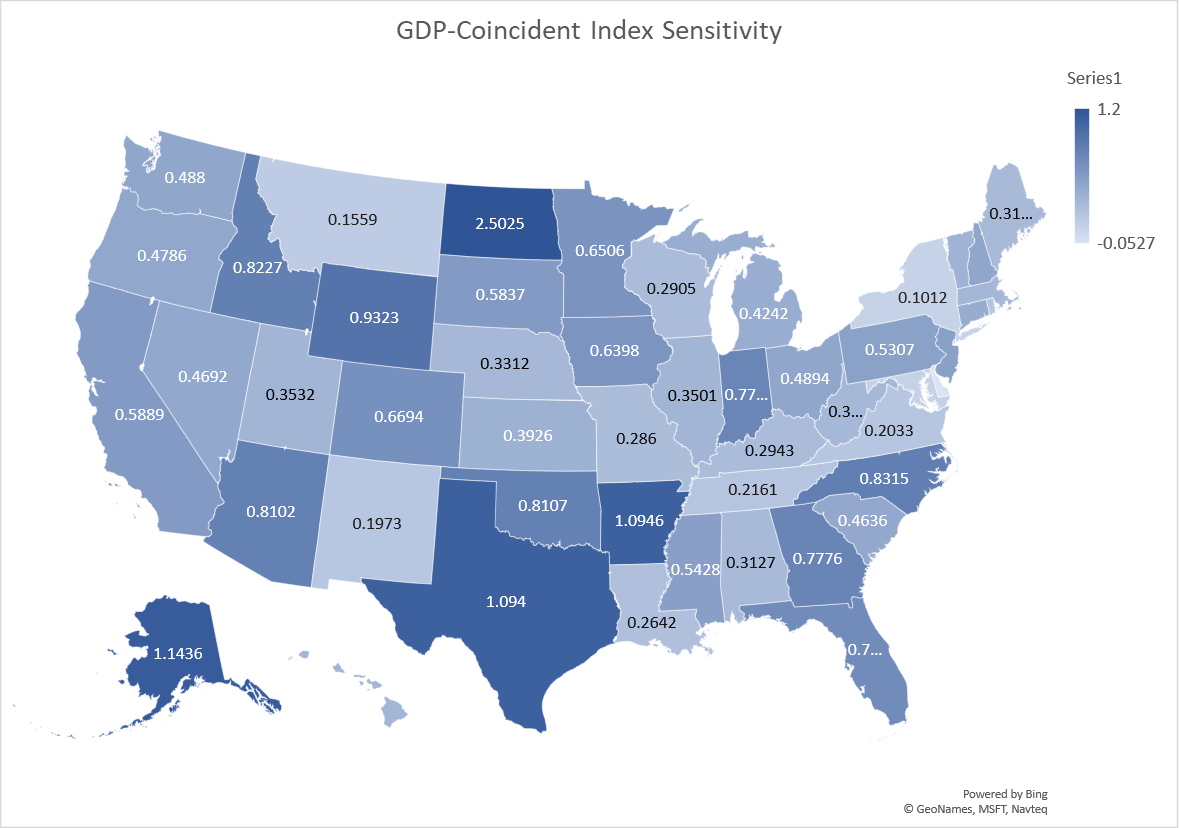
Figure 9 from Chinn-LeCloux (2018): Sensitivity of GDP growth to Coincident Indicator growth, quarter-on-quarter.
The following figure is a histogram of the estimated β’s.
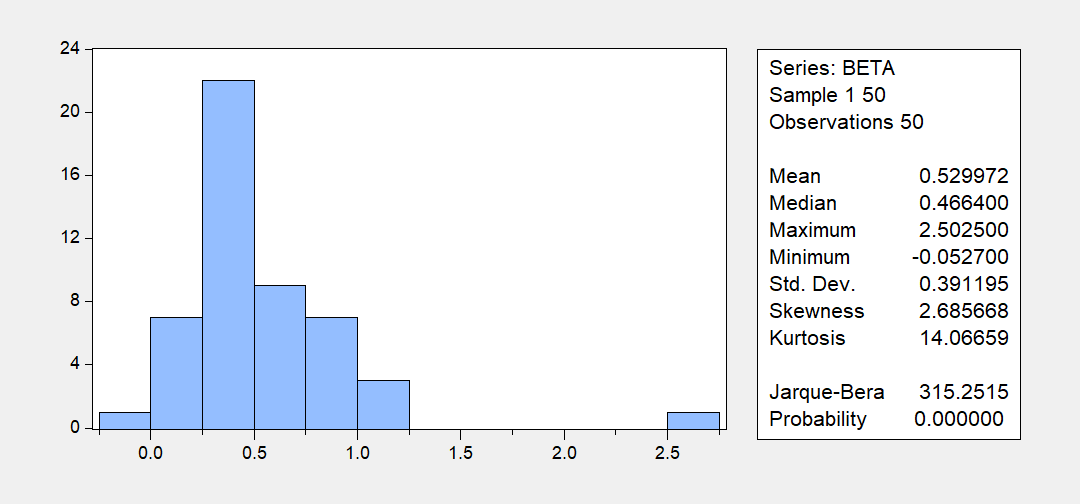
Figure 1: Histogram of estimated β’s.
At various junctures, certain observers have criticized the use of the Philadelphia Fed coincident indicators (e.g., [1], [2], [3]; Ironman asserted cross-state comparison of these indices is an example of “junk science”), and advocating the use of civilian employment, to track economic activity in Kansas, or Wisconsin. In the paper, we spend some time discussing why the civilian employment series from the household survey is a particularly difficult series to use in real time tracking of state level economies.
Assuming GDP is the best proxy measure for economic activity, it looks like the coincident indicator, income and nonfarm payroll employment are good proxies; civilian employment is not. For Kansas, the coincident index is highly significantly correlated with GDP, with a sensitivity of 0.39. For Wisconsin, nonfarm payroll employment and the coincident indicators are significantly correlated. The sensitivity of GDP growth to coincident growth is 0.29.
Some states do not exhibit any correlation of GDP with any of the standard measures: Alaska, Maryland, Missouri, and New Mexico. Interestingly, for New York state GDP only correlates only with personal income.
Using Quarterly GDP Data to Compare Performance against a Counterfactual
In one section of the paper, we use the quarterly GDP series for Kansas to assess whether the 2012 tax cut legislation, fully implemented in calendar year 2014, had the desired effect. At the time, Governor Brownback asserted that the tax program would act like a “shot of adrenaline”. The outstanding question then is whether output rose as a consequence of this measure.
As we note in the paper, this is a difficult question to answer completely, as it would require a fully fleshed out model, with explicit stances taken on causality, and the channels whereby which the tax measure affected economic behavior. With minimal data available at high frequency and in near reeal time, what can one do?
A reasonable approach is to see if output differed from what it otherwise would have been in the case of no tax cut. That requires the construction of a counterfactual, taking a stand on what is kept constant and what is not. We construct a counterfactual GDP series by using data from 2005-2013 period (2005 is the beginning of the quarterly state GDP series, 2013 is just before the tax plan is fully implemented.)
The counterfactual is created using an estimated error correction model, where c is a real commodity price index for Kansas.
ΔytKS = 0.478 – 0.190 yt-1KS + 0.182 yt-1US + 0.945Δ ytUS + 0.123Δct-1 + ut
Adj-R2 = 0.42, SER = 0.0124, N = 35, Sample 2005Q2-2013Q4. DW = 2.04, Breusch-Godfrey Serial Correlation LM Test = 1.19 [p-value = 0.32]. Bold face denotes statistical significance at 10% msl, using HAC robust standard errors. The Box-Ljung q-statistics for up to 8 lags does not reject the null of no serial correlation.
This model, when simulated dynamically out of sample, using realized values of US GDP and the real commodity price (what is called an ex post historical simulation) yields the following conclusions:
We find that actual Kansas GDP is at times far below predicted (5.9 billion Ch.2009$ SAAR, or 4.2%, as of 2017Q3). In other words, given the evolution of US GDP and commodity prices, and the historical correlations that held until 2013Q4, economic output was below expected. However, given the imprecision of the estimates, the shortfall is not statistically significant, even at the 40% level.
This result is shown in Figure 12 from the paper.
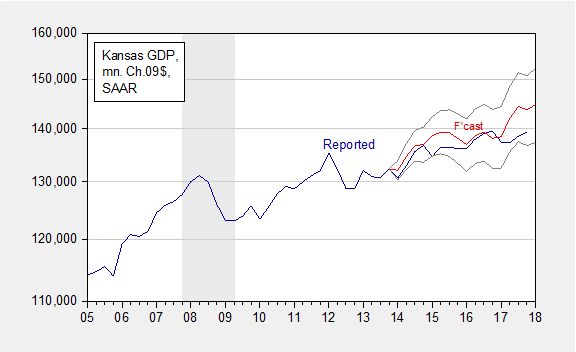
Figure 12 from Chinn-LeCloux (2018): Kansas GDP as reported (blue), and forecast (red), and 60% prediction interval (gray lines), all in millions Ch.2009$, SAAR. NBER defined recession dates shaded gray.
In another assessment, using a longer sample of data on coincident indices, which affords more precise estimates, I’ve found the gap to be statistically significant. (By the way, one analyst appealed to drought as an explanation for underformance, by subtracting out agriculture; but in that case, they did the subtraction of real terms incorrectly, invalidating the analysis.)
Conclusion
With the advent of quarterly GDP series, analysts are better armed to analyze business cycle developments in state level economies than they were before. Nonetheless, other indicators — employment, income and the Philadelphia Fed’s coincident indicators — will continue to be of use, perhaps even more useful in some cases than others.
The paper is here. Constructive comments welcome.
An increase in employment may coincide with a decrease in government spending, which may understate the explanatory power of the employment variables on GDP growth.
This is sort of like saying snow is consistent with hot weather. Both absurd and irrelevant to the post. Troll on Peaky!
Pgl, another absurd and irrelevant statement.
Get real.
PeakTrader: It would have to be a pretty strong counter-correlation to induce this effect.
Isn’t this what normally happens in the early stages of a recovery?
On page 8: the household survey applies to 60,000households. Obviously, with many, many more households than establishments
Is that right? I would have thought there were many, many more establishments than households.
Menzie I think that what you meant to say on page 8 was that the establishment data represents a nearly full population, but the household survey (even at 60,000 households) represents a much smaller subset of the total household population. And with states the sample size is even more of a problem. Anyway, I think that paragraph needs a little cleaning up.
As bad as state level statistics are, they are even worse at the individual county level.
This has important implications because Republicans are trying to institute illegal “work requirements” for Medicaid recipients in Michigan, Indiana and Kentucky. Republicans provide exemptions for work requirements in counties that have unemployment rates above a certain threshold. Curiously, just by coincidence I’m sure, these higher unemployment counties exempted from work requirements for Medicaid tend to be rural and overwhelmingly white.
But unemployment measurements in these low population rural counties are very suspect. They would be represented by a sample of only 20 or 30 households for the entire county. The confidence interval might be larger than the cut off thresholds they are intended to measure.
Republicans, dumb as ever. That is, dumb racists.
Has anyone tried using Vehicle Miles Traveled data? It is released monthly at the state level. Obviously noisy but seems like it could add something.
Menzie, your previous post https://econbrowser.com/archives/2018/07/thinking-about-macro-data-and-revisions-and-recessions-a-cautionary-tale adds more concern about GDP data in general. I realize it’s the best available, but one wonders with today’s ability to accumulate and process large quantities of data why we seem to be stuck in the 20th century with regard to economics data. It’s as if legacy systems are an anchor against progress. Today’s computing power should enable real-time acquisition and analysis of important data. https://www.nextgov.com/cio-briefing/2016/05/10-oldest-it-systems-federal-government/128599/
If this were a priority, there would be fully integrated state/federal systems. But with old, fragmented systems it is virtually impossible to get more than a very coarse picture of economic changes at the state and local level. All of the statistical manipulating is, it would seem, just putting lipstick on a pig. Still, as my grandmother used to say, “It’s better than nothing, dear.”
Menzie, an opportunity for you to provide your insights? https://www.commerce.gov/news/blog/2018/06/white-house-releases-first-quarter-milestones-leveraging-data-strategic-asset
Bruce Hall: Actually, BEA is always updating the way it compiles data. Same for BLS. I don’t know how many seminars I’ve been in where people are incorporating scanner data, big data, etc. Banque de France had a conference on introducing big data into GDP, other macro series. But for a cautionary tale, see this guest post.
Menzie, good post on Google big data. It’s interesting that those who control data feel the need to “massage” the data before it’s released. At a minimum, the raw data></B should be provided with the filtered/massaged/tweaked data… along with the reasons for the alterations and, possibly, the algorithms use to alter the data. That way, researchers, etc. could determine if the alterations to the data were appropriate.
We've seen how pre-election polling data was gathered and adjusted and dead wrong. So it is important that the sample characteristics be available if sampling is the method for building databases. And then sometimes it's just a matter of GIGO.
That's why arguments exist: https://wattsupwiththat.com/2017/07/06/bombshell-study-temperature-adjustments-account-for-nearly-all-of-the-warming-in-government-climate-data/ . and https://wattsupwiththat.com/2016/05/20/changes-to-the-giss-land-surface-air-temperature-based-dataset-have-increased-reported-long-term-global-warming/
Without adequate agreement regarding the reasons for and the the method of adjustments to data, this kind of bickering continues.