[Updated to include CoRev’s analysis of trends 4/16/2019] I have repeated requests for raw data used in this post, part of which is plotted in this graph. Reader CoRev writes:
…Menzie has admitted he mis-attributed his full range of sources used, and has yet to provide ALL the data he used.
This is not true. I didn’t admit mis-attribution. All I can conclude is that there is some confusion over terms.
First, there is some confusion over whether the data differs between BLS, or BLS via FRED.
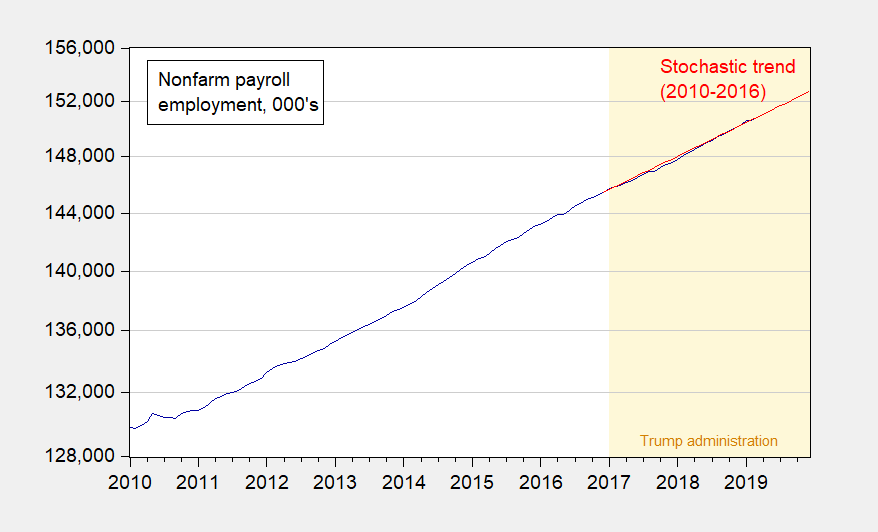
Figure 1: Nonfarm payroll employment (dark blue), and stochastic trend (red). Stochastic trend estimated using 2010-2016 data, and regression of first log difference on a constant. Source: BLS March 2019 employment situation release, and author’s calculations.
Just to verify, the BLS series and the FRED data are the same. Here are the datasets.
The data links were added to the original post upon CoRev’s request. But now it’s alleged that I have not provided all the raw data. This statement is wrong, in my book.
The only missing data is the red line is data calculated by me using an ARIMA(0,1,0) on log PAYEMS. That is not included as “raw” data — it’s not my definition of “raw” data — but here for completeness is the forecast series I generated:
Author’s calculated random walk w/drift
Further, CoRev alleges:
Creating a smoke screen to avoid providing the actual data for replication or further analysis.
I will merely point out I am not responsible for the paranoid among us to be unable to re-create a random walk with drift forecast.
Update, 4/16/2019, 9AM Pacific: Reader CoRev has provided his check-file on my trend analysis. Without comment, here it is:
Meanwhile, back at the CoRev lair……..
https://youtu.be/dYDxxHrlmUg?t=8
Love that movie!
What’s Up With the Ending?
https://www.shmoop.com/psycho/ending.html
“And if this evil can be buried for so long, how many others are out there, beneath the mud? The final, ominous sawing of Bernard Hermann’s score doesn’t suggest a happy resolution, so much as an ongoing anxiety at what, next, might be hoisted up into the light.”
So it is with the incessant trolling from CoRev. It is evil as it is all a lie. But point out the lie and many more come flying out of his mud factory.
“This is not true. I didn’t admit mis-attribution. All I can conclude is that there is some confusion over terms.”
This is how Team Trump teaches its minions. Any sane person reading those comments would realize that CoRev and his minnie me Princeton Stevie were both incredibly confused but persistent about accusing you of manipulation. Even with very patient explanations that FRED was reproducing BLS data – updated the same day as the April 5 release (which Stevie said did not exist) – they lobbed all sorts of false accusations that either BLS or FRED got things wrong.
In the smoke and confusion that these two trolls deliberately created – they decided to declare victory.
Yea, it is dishonest, a waste of time, and beyond childish. But look at their leader – he does the same thing several times a day.
My two personal favorites:
(1) Stevie says JOLTS is better than BLS data even though JOLTS is produced by BLS. His graph of JOLTS data – cut and pasted from Bill McBride. No data sourcing or verification, Just a cut and paste job. And this troll complains the rest of us use FRED graphs?
(2) CoRev cites increases over time in NOMINAL tax revenues never bother to do inflation adjusted figures. His excuse? We do not take temperature readings and deflate by the CPI index! Now that is a clever way to deny global warming!
Menzie using an ARIMA(0,1,0) on log PAYEMS.
Better restate that you included a constant in the ARIMA (0 1 0) or CoRev will accuse you of being deceitful. Never mind that the you said it was a random walk with drift. Why do people think they know something about time series analysis when they don’t understand Box-Jenkins 101?
Oh my – this talk of ARIMA models has CoRev confused. So he called Stephen Moore for an explanation. After all Moore will be on the FED so he has to be a smart fellow – right?
Moore got a little nervous when he heard “model” and thought ARIMA was the name of the latest playboy model Trump has been hitting on. So he asked CoRev not to tell Melanie!
Menzie, a little touchy are we? Wouldn’t it just have been easier to notify me that you had updated the older article with the link, instead of writing 2 more articles and a multitude of comments?
CoRev: Several comments addressed to you directly pointed out the data were now posted. they asked you for what you were going to do with the raw data now that it was up. Don’t you read the comments, when you are posting comments?
Also, I’d like to see your trend line estimate that you deem superior.
Yea we should be used to your incessant intellectual garbage and childish cheap shots by now. You do it 24/7 so HEY!
BTW blog posts are not exactly articles. I guess that is why the American Economic Review has given up on reading your “contribution” to soybean economics!
“it just have been easier to notify me that you had updated”.
What on earth do you think has been updated? BLS released that employment report on April 5. There has been no follow-up release. FRED updated its series the same day as they CLEARLY explain in their charts etc. You might want to explain that fact to your fellow village idiot since Princeton Stevie boy thinks FRED data had lagged the BLS reporting. Of course his reading abilities are on par with yours!
CoRev The BEA is having a little trouble scrubbing the raw data of residual seasonality effects. Maybe you could lend your expertise and deep knowledge in data analysis and offer a little help. Thanks in advance.
https://www.clevelandfed.org/newsroom-and-events/publications/economic-commentary/2019-economic-commentaries/ec-201905-residual-seasonality-in-gdp-remains-after-bea-improvements.aspx
I can see you’re a man after Not Trampis’s own heart.
I’ll tell you what observing roughly half a human lifetime of human behavior has told me about these things. What is the real seedling of all of this. What is the little green sprout (as Bernanke might say) of all of this “raw data” discussion??? CoRev is upset he made a complete A$$ out of himself on his soybean market comments. So he can’t look in the mirror in the morning and realize he has one person to blame for making an A$$ of himself on the soybeans discussion—-so we wander over into nonsense about raw data. Well, CoRev “wants to know what the raw data is” and where he can find it. Tell me, when they have the House of Representatives hearings related to the full Mueller Report are we going to have to tell CoRev which internet streams or TV networks he can find that on??
Here is just an honest to God straight and open question: Do you think a person who couldn’t find BLS or FRED data in a Google search, could “said person” get a high school diploma or GED?? You be the judge.
Hmm,
This shows the decline of US Education.
I learnt all about data sources in my very first year at University down under. Indeed I can’t see how anyone could write an essay in any economics subject if they did not understand the data series. In terms of econometrics it would be impossible
I’d be highly offended by your disparagement of American education, if there weren’t a degree (no pun intended) of TRUTH in it. K-12 starting to suck pretty bad, but at least our universities are still good.
Dear Folks,
I think CoRev is wrong in making such a fuss about Menzie’s using the ARIMA model, and all these arguments about how FRED and BLS data differ are absurd. But it would make some sense for Menzie to just tell us the basis for the ARIMA(0,1,0) model. That you don’t get moving average terms showing up most of the time is granted, but I would like to see the results for the autocorrelation checking. The payroll employment results just look like they were smoothed out, and seem basically unchanged. A forecast with just straight differences is going to stop having deviations from a constant straight line after a while, and that looks like what there is. It’s not raw data; it’s just a forecast, and it can be wrong or right.
J.
@ Julian Silk
You are under the impression it appears, that professors have time to explain statistics to their students. Those are usually prerequisites for the classes Menzie teaches. Even in most freshman classes, Economics profs are not going to sit around explaining calculus, statistics etc. That’s why you have general requirements or prerequisite classes. Now, for a blog, if Menzie wants to humor readers (he’s often kind enough to do so) that’s his prerogative. The phrase that enters my head, and why some teachers and professors are not as kind as Menzie and Professor Hamilton are is “Give them an inch, and they’ll take a mile”. This entire blog is Professor Chinn’s and Professor Hamilton’s non-obligatory gift to all of us. They do this out of their own generosity (with a very very mild intention of some promotion of their own work).
I think some readers here need to get a clue and realize some people only have so many hours in the day—and maybe be thankful and appreciative for what is offered here and the extensions of kindness that are already made. Many professors don’t “extend” themselves the way Menzie and Professor Hamilton do.
To do that and then be attacked by readers??? It’s pretty amazing to me.
Julian Silk: It’s not really a forecast, but rather just a trend. For me, then, it’s mostly an issue of whether to use a deterministic trend or a stochastic trend. Then my philosophy is to apply tests with unit root null, tests with trend stationary null, and — if there’s a failure to reject the difference stationary null — then apply tests for structural breaks which might yield a presumption of a unit root when segmented stationary trends is more appropriate.
See Cheung and Chinn (OEP 1996) and Cheung and Chinn (JBES 1997) for examples.
Dear Menzie and Folks,
OK, that’s fair enough. I thank Menzie for stating what it is. I’m not going to argue with preferences, being labeled a monster so often for my own. It’s just being clear.
J.
CoRev writes so much intellectual garbage, one might miss the best lines such as this one:
‘Menzie has admitted he mis-attributed his full range of sources used, and has yet to provide ALL the data he used.’
What exactly did Menzie not provide in terms of data he used for his graph. Good thing he color coded this (Bob Barr is taking notes). The blue line is actual employment. If CoRev does not realize that ALL the data used for the blue line is provided either by FRED or BLS (which BTW give precisely the same numbers – something lost on Princeton Stevie boy) then he is dumber that we thought.
Oh yea – there was that red line which Menzie clearly stated was constructed using his ARIMA model.
Hey CoRev! FRED does not provide the output of the ARIMA model. Hehe – CoRev thinks he made a point here but the rest of us know better!
As far as color coding – we’ll see if Bob Barr releases all of the information in the Mueller report. My bet? RUDY gets to black out all references to Donald Trump!
“It’s tough to make predictions, especially about the future.” Yogi Berra
Menzie in this article: “This is not true. I didn’t admit mis-attribution. All I can conclude is that there is some confusion over terms.”
Menzie in the last article: “Pretty sure I got the BLS nonfarm payroll series from BLS but you are right, it is *possible* I downloaded from FRED (I know the file I posted in response to CoRev’s request is definitely from FRED).” I never noted the file was updated.
title
BTW, for those wondering why I didn’t note the “Update”, I seldom re-read the base article unless (Updated) is in the Title. I remember some here used to Copy the original version of an Article and then compare over time looking for undocumented changes. Yes, they did find interesting results.
CoRev: But several individuals directed comments to you by name, asking what results you got, given that the data were now posted. I take it you do not read comments either — just shoot from the hip, bullet after misdirected bullet. And you didn’t even try getting the data yourself after others directed comments to you that told you where to det the data?
I am forced to say you are even more deficient than my undergrads that receive D’s.
Maybe CoRev is hoping for grade inflation!
I asked you what data he updated. Oh right – he did not update any data because there has been no new releases from BLS.
Oh he altered the title of his graph Big F&&&ing deal.
Oh this stupid whining from you and Princeton Stevie boy over the title of a graph? Can you be more stupid? Scratch that – we know you will.
Pgl, please learn to read. Your comprehension is atrocious. You asked: “What exactly did Menzie not provide in terms of data he used for his graph.” The answer is simple, the data he used in his analysis. Providing a link to his source(s), when I asked for: ” Can you provide the raw data used?”
Menzie, ” But several individuals directed comments to you by name, asking what results you got, given that the data were now posted.” Is this the comment to which you refer: “Okay, now that you know the raw/source data and where to find it, dazzle us with your alternative analysis.”?
At that point I had not noticed that you had updated the previous article with the link to the source. I didn’t realize the article had been updated, even with Steven Kopits discussion of sources. I did not see the update until last night. I don’t usually re-read the article, and do a search through comments by name or data. Accordingly, missed your update until last night.
I am now doing my own trend analysis.
I have completed my own trends, and I agree with Menzie’s initial conclusion. I used an anomaly based comparison, as that is what I am familiar with when handling temperature data. I did 3 graphs with different baselines. They were the whole data set starting at 01/2008, Obama’s presidency and Menzie’s time frame.
My source was Menzie’s data: http://www.ssc.wisc.edu/~mchinn/PAYEMS.xls It took me ~ 1/4 hour after downloading the data. I still don’t understand the concern over releasing the data.
CoRev: There was no concern over releasing the data. It’s just I didn’t think I needed to upload the file to my SSC server, then put a link to the file online, given *that this was an entirely unexotic data series* and only you seemed to be surprised by the fact that a stochastic trend would yield these results.
If you want, I will post your series. Just send to me in an Excel file.
Wait a second. You had to rely on a third hand source. BLS compiles the data. FRED reproduces it. Menzie also reproduces it. And a village idiot like you cannot go to BLS? OK!
Of course you say you did a “trend analysis” which confirms what Menzie originally wrote. Thanks for the massive waste of time!
BTW – you cannot articulate what you did to construct this incredibly excellent trend analysis. Go figure!
CoRev starting at 01/2008, Obama’s presidency and Menzie’s time frame.
I think you mean starting with Bush 43’s presidency.
Anomaly data is just a way of displaying deviations in data relative to some baseline. I have no idea how that tells you whether a time series is an I(1) stochastic trend or an I(0) deterministic trend. Maybe all those unit root papers were for nothing.
OK, sent.
2slugs, I wrote what I meant. I was looking for a test where there was KNOWN structural break. And, your grasp of the obvious is impressive: “Anomaly data is just a way of displaying deviations in data relative to some baseline.”
Pgl, you are so clueless you amaze.
Menzie, pardon me for being cynical, but I have seen too many egregious errors in papers, studies, and especially blog articles to trust any more. Being mocked for a simple request and/or questioning doesn’t add to the trust. Starting at best as a skeptic (a normal scientific position), failing to provide data or answer questions with mockery just adds to the skepticism/cynicism.
CoRev I think you misunderstood my comments. My first comment was simply correcting your recollection of who was President in Jan 2008; it was Bush 43, not Obama. My second comment expressed wonder at why you would want to work with anomalies. It’s especially puzzling if you wanted to transform the negatively signed anomalies into logs.
Lord – either you know you are both ducking the questions AND flat out misrepresenting every single word or you have truly gone insane. Do you even know how many variables Menzie graphed? Hint – count to one. Oh wait you never learned to do even that!
“At that point I had not noticed that you had updated the previous article with the link to the source.”
Mother of Pearl! BLS release was on April 5 at 8:30am EDT. FRED updated their reporting of the EXACT SAME DATA (it was a single series after all). So the word “update” would be used with someone with an IQ in the single digit. Which is CoRev and Princeton Stevie to a tee.
Can you two morons get more idiotic? Never mind – you will !
I forgot to add it is in ODS format.
Never mind the format for saving whatever “data” you have. You failed to tell us where you sourced your “raw” data and when primitive stats package you use for ARIMA analysis. Oh wait – you have no clue what ARIMA means. So skip that and just let Menzie know what malware you have placed in your ODS file!
Pgl, what an embarrassment to humanity. You failed to tell us where you sourced your “raw” data
My source was in the comment above: “My source was Menzie’s data: http://www.ssc.wisc.edu/~mchinn/PAYEMS.xls ” There are many ways to skin a cat and to do trend analysis. I’ve explained my approach and why several times now. But, you might want to explain your comment: “and when primitive stats package you use for ARIMA analysis.” When?????
You are an amazement.
CoRev – Menzie, pardon me for being cynical, but I have seen too many egregious errors in papers, studies, and especially blog articles to trust any more.
I guess CoRev spends all of his time reviewing his own writing. Yes – egregious errors abound!
Menzie, thanks for putting up my alternative analysis without comment.
CoRev It doesn’t make a lot of difference, but it looks like you’re identifying Menzie’s start date as Oct 2009. I believe he started with Jan 2010. I’m thinking you might have understood Menzie as meaning FY2010 rather than CY2010.
I misplaced the label. The calculation starts with 01/2010, B25 not B22.
Thanks for looking, though.
CoRev I misplaced the label.
Okay. Been there, done that.
I don’t know if you did any additional analysis not shown on the spreadsheet, but the issue has never been whether or not there was a trend in the data; the issue was always whether it was a stochastic trend or a deterministic trend, or more formally, an I(1) or I(0) time series. Plotting the anomalies from levels data shows an upward trend after 2010, but that was never the issue. Determining the order of integration (i.e., I(1) or I(0)) requires one or another kinds of formal tests. Visually a stochastic trend might look like a deterministic trend, but econometrically they are very different animals. For example, stochastic trends are nonstationary, so you would not be able to regress a nonstationary stochastic trend against a stationary time series. And if you want to regress variables that or all nonstationary, that’s when you start getting into all that stuff about cointegration and error correction models that Menzie sometimes uses.
2slugs, your issue was never mine, since I intended using a different approach.
My basic/simplistic interpretation of: “Deterministic vs stochastic
In probability theory, a stochastic process, or sometimes random process, is the counterpart to a deterministic process (or deterministic system).” makes me consider employment data NOT RANDOM. Clearly temperature data also falls into this category.
Are they both, employment and temperature, not auto correlated? If you ran a test and found them to be random, then I would be concerned with some one messing with the data. Some of these tests may be considered best practices for statisticians, but how often do some test need to be run on the same data set(s), even if updated, to make the same determination?
CoRev Temperature and employment data in level form are most certainly autocorrelated. That’s the problem. With apologies for oversimplifying, consider this time series equation:
Y(t) = (phi)*Y(t-1) + e(t)
In English, this says that the current value (Y(t) is equal to the past value Y(t-1) multiplied by some coefficient “phi” plus a random white noise error term e(t).
If “phi” is greater than 1.00, then the time series is explosive, which makes it nonstationary.
If “phi” is less than 1.00, then eventually the time series will converge to a stationary state. A small value of “phi” means that the series will converge fairly quickly because the errors and shocks from previous time periods decay rapidly. A large value of “phi” (e.g., 0.95) means that it will take a long time for the series to converge because a lot of the values from previous periods will carryover to the current period. A large “phi” means the series will be slow to decay.
If the “phi” is exactly 1.00, then 100% of the previous period’s shocks and white noise error term will get perpetuated into the current value of Y(t). The series will tend to wander. Error terms and shocks accumulate forever and never decay. That is a random walk.
Now consider adding a constant term to the earlier equation:
Y(t) = constant + (phi)*Y(t-1) + e(t)
This is a random walk plus a constant term. The constant term gets added to the random walk. This is called a random walk with drift. If you go out far enough the drift term will eventually dominate and what you will see in a graph is something that looks like an obvious trend line.
A deterministic trend looks something like this:
Y(t) = constant + (beta)*(time) + e(t)
The beta*time trend is trend stationary and does not wander…it just goes in a straight line…or a quadratic curve if you use time-squared…or whatever.
2slugs we agree! “Temperature and employment data in level form are most certainly autocorrelated.” Now add a sinusoidal patter to temperature. Which is what I’ve been trying to teach you for years with my comments about cycles, daily, seasonal, multiple ocean (ENSO, AMO, PDO (their synchronizations) and more independent some still unknown), solar and finally glaciations. Yet, the focus is on the dirty and incomplete recorded temperature, which does not even cover a full set of the shorter cycles. Just looking at their impacts over the glacial cycles ends up with https://saltbushclub.com/wp-content/uploads/2019/04/temperatures.png?fbclid=IwAR3tF37Vpz_Br6gNSpORPKimDhbIL0Sohqb2UU5EeOrOghvwqhC0zb4-bYk (Yes, I know this is for the NH, but so is the bulk of the temperature record. Which is more limited to being land-based and concentrated in a very few populated locations.) And yet all the drama is trying to explain the latest peak, BADLY project where it goes in a few decades, while totally ignoring all the previous peaks and valleys in the geological record.
Let’s get back to the subject at hand, graphing a highly autocorrelated employment trend using a stochastic/random formula and forecasting. What value is the forecast after the months of articles citing the importance of policy uncertainty, policy impacts, chance for an impending recession, etc. If you note my questions the focused on the Menzie’s selection of best test, remember my universe includes methods other than statistics. I just wanted to confirm his trend using my own method, accordingly using HIS data was necessary, because he added “author’s calculations).
I refer you to Julian Silk’s comments: “… The payroll employment results just look like they were smoothed out, and seem basically unchanged. A forecast with just straight differences is going to stop having deviations from a constant straight line after a while, and that looks like what there is. It’s not raw data; it’s just a forecast, and it can be wrong or right.”
and
“Dear Menzie and Folks,
OK, that’s fair enough. I thank Menzie for stating what it is. I’m not going to argue with preferences, being labeled a monster so often for my own. It’s just being clear.”
You and I have similar backgrounds and different educations and interests. Neither is better or worse, just different. Being attacked for the differences is just another form of bigotry. Some here go far beyond this level.
As always I comment Menzie for allowing these kinds of discussions. We all learn from them.
commend not comment
CoRev add a sinusoidal patter to temperature. Which is what I’ve been trying to teach you for years with my comments about cycles, daily, seasonal,
I think I understand Unobserved Components Models as well as the next guy. Maybe a little better.
I suspect there’s a big gap between your understanding of time series analysis and academia’s understanding. At this point I can only recommend spending a few months working through undergrad texts on the subject. I’m sure we’ll have plenty of opportunities to rehash all this stuff….yet again.