Today we are fortunate to present a guest post written by Baptiste Meunier (ECB). The views expressed in this paper are those of the authors and not necessarily those of the institutions they are affiliated with.
In a recent NBER working paper (Chinn, Meunier and Stumpner, 2023), coauthored with Sebastian Stumpner (Banque de France) and Menzie Chinn (UW), we nowcast world trade using machine learning methods. The reason for nowcasting global trade is straightforward: official statistics are published with some delay (two months) while multiple early indicators are available in the meantime. The use of machine learning techniques responds to trade growth being highly volatile, much more than other macroeconomic variables like GDP or employment. Our idea is that using non-linear techniques, best exemplified by machine learning, could improve the accuracy of predictions. Two key lessons emerged from our paper – that might be useful for other forecasters – are detailed in this post.
Lesson 1: among non-linear models, machine learning techniques based on linear regressions appear to perform better – though they have been much less in the literature so far
As we tested over a range of different machine learning techniques, an important ingredient in our study is the distinction between those based on trees and those based on regressions. The first category includes random forest and gradient boosting and works by aggregating several decision trees together. It is the most widely used in the literature, notably random forests that gained in popularity over recent years. The second category is an adaptation of the first but using linear regressions instead of, or in complement to, decision trees. It comprises macroeconomic random forest (Goulet-Coulombe, 2020) and gradient linear boosting, two innovative methods that have received much less attention in the literature so far.
Nevertheless, machine learning techniques based on regressions outperform other techniques significantly and consistently across different horizons, real-time datasets, and states of the economy. They outperform tree-based methods which – despite their increasing popularity in the literature – perform poorly in our setup. This supports recent evidence that such techniques might be ill-equipped to deal with the short samples of time series in macroeconomics. Comparing more broadly, we find that regression-based machine learning techniques also outperform more “traditional” techniques, both linear (OLS) and non-linear (Markov-switching, quantile regression), again significantly and consistently.
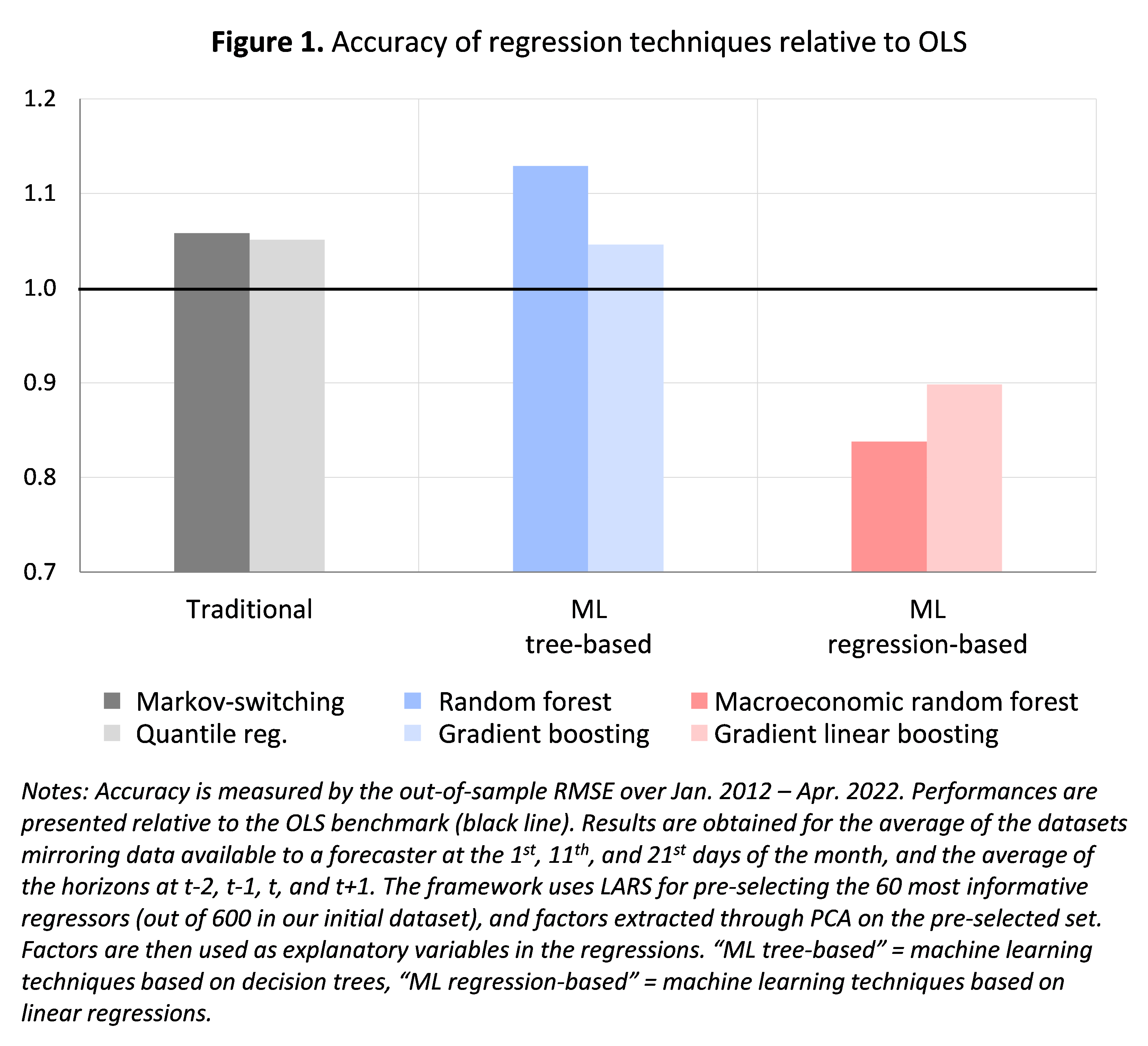
Individually, the best-performing method is found to be the macroeconomic random forest of Goulet-Coulombe (2020), an extension of the canonical random forest. This is visible in figure 1 which represents the accuracy (measured by the out-of-sample RMSFE over 2012-2022) of the different techniques relative to the OLS (= 1, figured by the black line). “Traditional” non-linear techniques (in shades of grey) and machine learning techniques based on trees (in shades of blue) fail to improve over the OLS benchmark, and even have slightly worst accuracy (indicated by their RMSE being above the black line). Machine learning techniques based on linear regressions (in shades of red), by contrast, outperform the OLS benchmark by 15-20% on average – and therefore also outperform the other non-linear techniques. Among these techniques, best in class is the macroeconomic random forest (dark red). Beyond the results presented in figure 1, averaged over horizons and real-time datasets, evidence in our paper shows that these results hold true across different horizons, real-time datasets, and states of the economy.
Lesson 2: doing preselection and factor extraction on the input dataset appears to enhance the accuracy of predictions based on machine learning
In order to maximize the accuracy of machine-learning-based forecasts, our paper proposes a three-step approach composed of (step 1) pre-selection, (step 2) factor extraction, and (step 3) machine learning regression. It is motivated by the literature: for instance, Goulet-Coulombe et al. (2022) suggest that machine learning techniques are more accurate when used in a factor model. And doing pre-selection in factor models responds to another literature (Bai and Ng, 2008) that found that selecting fewer but more informative regressors improve performances of such models. Our framework combines these two strands and apply it to a range of machine learning techniques.
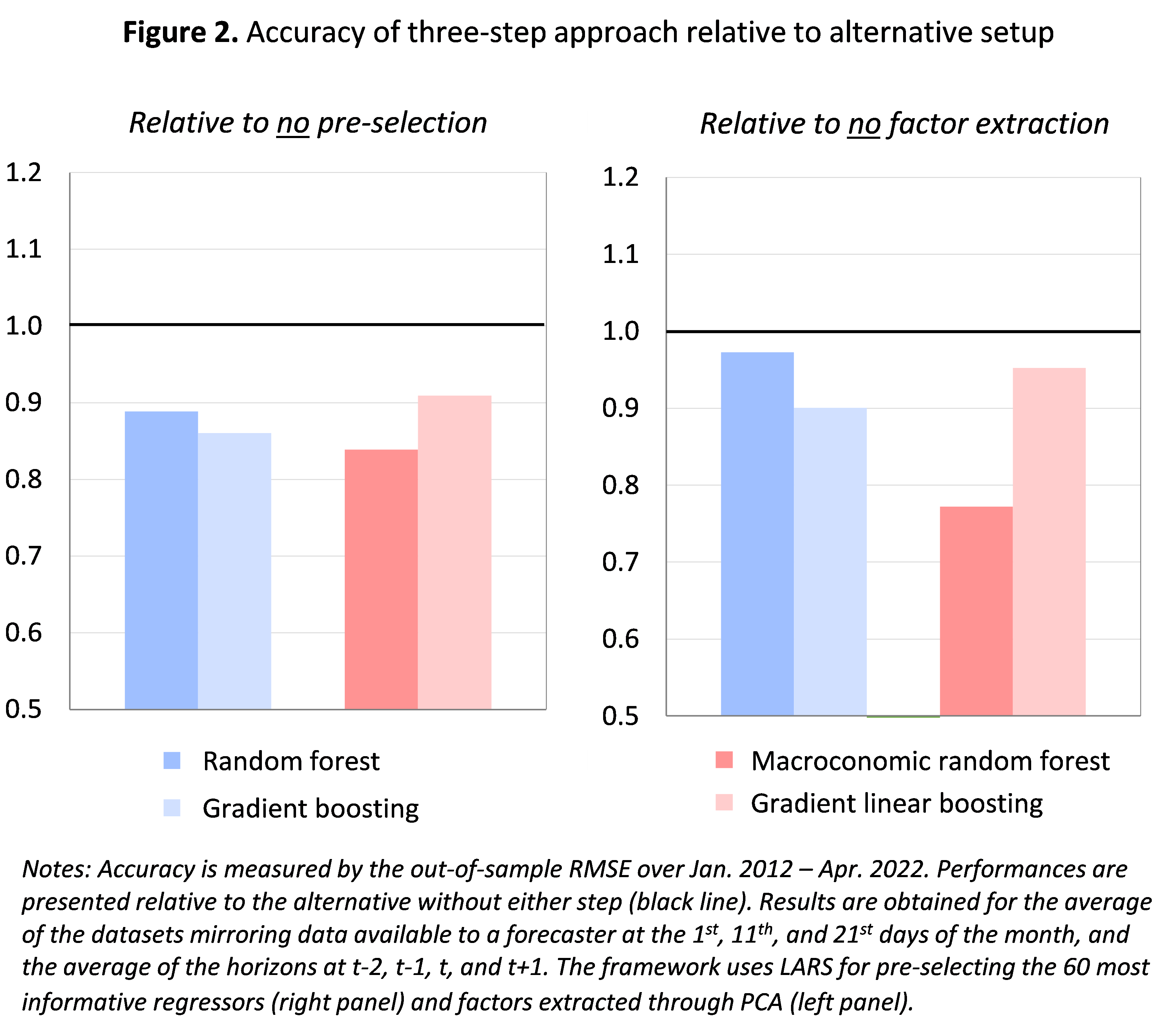
Both pre-selection and factor extraction improve the accuracy of machine-learning-based forecasts. In our setup, adding a pre-selection enhances predictive accuracy by around 10-15% on average. Pre-selection can therefore be useful also for machine learning techniques, despite the common idea that such techniques are set to handle large datasets of irrelevant variables. Similarly, using factors provides more accurate predictions than using all individual variables as regressors, with accuracy gains also around 10-15% on average. This is shown in figure 2 which presents the accuracy of the three-step approach relative to alternative setups where we skip the preselection step (left panel) or the factor extraction step (right panel). In both cases, the accuracy of the three-step approach (showed by the coloured bars corresponding to the different machine learning techniques) is better than the alternative (black line at 1). Once again, results are averaged on figure 2, but disaggregated results (available in the paper) yield similar conclusions.
Finally, on our setup the three-step approach significantly outperforms other workhorse nowcasting techniques. It first outperforms the widely used “diffusion index” method of Stock and Watson (2002) that uses two steps: factors extraction via Principal Components Analysis (PCA) and OLS regression on these factors. Compared to this method, the three-step approach can be viewed as an extension towards pre-selection and machine learning. Our approach also outperforms a dynamic factor model, a technique widely used in the nowcasting literature. Finally, we also tested across a range of methods for pre-selection and factor extraction and find that the best combination – in our setup – is given by the Least Angle Regression (LARS; Efron et al., 2004) for preselection and the PCA for factor extraction.
In a nutshell, our own experience of nowcasting with machine learning offers two key lessons that are best summarized in the three-step approach we lay out. This framework can also offer a practical and step-by-step method for forecasters willing to use (or at least to test) machine learning methods on their favourite dataset. To make this easier, we share a simplified version of our code on GitHub.
References
Bai, J., and Ng, S. (2008). “Forecasting economic time series using targeted predictors”, Journal of Econometrics, 146(2), pp. 304–317
Chinn, M. D., Meunier, B., Stumpner, S. (2023). “Nowcasting World Trade with Machine Learning: a Three-Step Approach”, NBER Working Paper, No 31419, National Bureau of Economic Research [ungated version]
Efron, B., Hastie, T., Johnstone, I., and Tibshirani, R. (2004). “Least angle regression”, Annals of Statistics, 32(2), pp. 407–499
Goulet-Coulombe, P. (2020). “The Macroeconomy as a Random Forest”, arXiv pre-print
Goulet-Coulombe, P., Leroux, M., Stevanovic, D., and Surprenant, S. (2022). “How is machine learning useful for macroeconomic forecasting?”, Journal of Applied Econometrics, 37(5), pp. 920–964
Stock, J., and Watson, M. (2002). “Forecasting using principal components from a large number of predictors”, Journal of the American Statistical Association, 97(460), pp. 1167–1179.
This post written by Baptiste Meunier.
Perfect application; really nicely done.
If I read correctly between the lines, lags in reporting of trade data are problematic, so accurate estimates of trade data have value. Net exports figures are, for instance, a common source of mystery in GDP nowcasts.
So Menzie (et al), I’m going to guess that once you had what looked like improved net export estimates, you put them to use. If so, what kind of improvement did you get in using your estimates of trade data as inputs to nowcasts?
Could this estimation method be implimented across a large number of countries to generate an improved global trade snapshot? (Getting carried away, I realize.)
Before I retired I worked on a joint US Army/Canadian Defence Ministry project that looked at various approaches to predicting weapon system component failures. It turned out that a Support Vector Regression model outperformed every other traditional approach. The findings didn’t get a lot of traction because it all seemed kind of mysterious and opaque to senior leadership.
my crude understanding is that support vector machines is an approach where you take a number of preexisting characteristics, and analyze to determine which is the best model using those choices. so I would imagine it works well if your set of characteristics are robust and include all of the most important characteristics, in general. and experience guides you on which characteristics to include at the outset. but what happens if you are missing what turns out to be an important characteristic? did it still produce useful output?
This fine application is just what China has created for pinpoint and immediate weather forecasting:
https://www.nature.com/articles/s41586-023-06185-3
July 5, 2023
Accurate medium-range global weather forecasting with 3D neural networks
By Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu & Qi Tian
Abstract
Weather forecasting is important for science and society. At present, the most accurate forecast system is the numerical weather prediction (NWP) method, which represents atmospheric states as discretized grids and numerically solves partial differential equations that describe the transition between those states. However, this procedure is computationally expensive. Recently, artificial-intelligence-based methods have shown potential in accelerating weather forecasting by orders of magnitude, but the forecast accuracy is still significantly lower than that of NWP methods. Here we introduce an artificial-intelligence-based method for accurate, medium-range global weather forecasting. We show that three-dimensional deep networks equipped with Earth-specific priors are effective at dealing with complex patterns in weather data, and that a hierarchical temporal aggregation strategy reduces accumulation errors in medium-range forecasting. Trained on 39 years of global data, our program, Pangu-Weather, obtains stronger deterministic forecast results on reanalysis data in all tested variables when compared with the world’s best NWP system, the operational integrated forecasting system of the European Centre for Medium-Range Weather Forecasts (ECMWF). Our method also works well with extreme weather forecasts and ensemble forecasts. When initialized with reanalysis data, the accuracy of tracking tropical cyclones is also higher than that of ECMWF-HRES.
“A.I. Is Coming for Mathematics, Too”
https://www.nytimes.com/2023/07/02/science/ai-mathematics-machine-learning.html
And economics?
Even the most basic AI is better at arithmetic than JohnH. Heck my dog is better at arithmetic than you are.
Just think how many insults, snarks, and misrepresentations pgl could generate using AI! And he could clog up each thread with even more nonsense.
I have used symbolic algebra tools for years. while not AI, they are in the same family from a use case perspective. they make the user far more productive and less error prone. recently I have been using AI for some scientific work. once again, it is a great productivity tool. but it will not replace mathematicians, physicists, or economists-at least not in the next decade or more. the AI world cannot come up with the why on its own. that requires the human user, from my experience. it will enhance users with creativity, but devalue those whose strength is technical calculations.
honest practitioners will embrace AI. where I see frustration will be in the dishonest folks of the world. AI can be built to be both biased and unbiased (dishonest and honest). since it is a computer, it will ultimately determine answers in a binary capacity. it will be able to clearly determine whether an argument is based on falsehoods, and be able to identify those arguments to the user. people like trump or faux news should be worried, because the ultimate fact checker is on its way. AI can fact check faster than trump can speak mistruths.