Consider the plight of a time series econometrician who wants to do a quick and dirty forecast for the next year, conditioned only on past information on GDP. One might end up with series in the graph below.
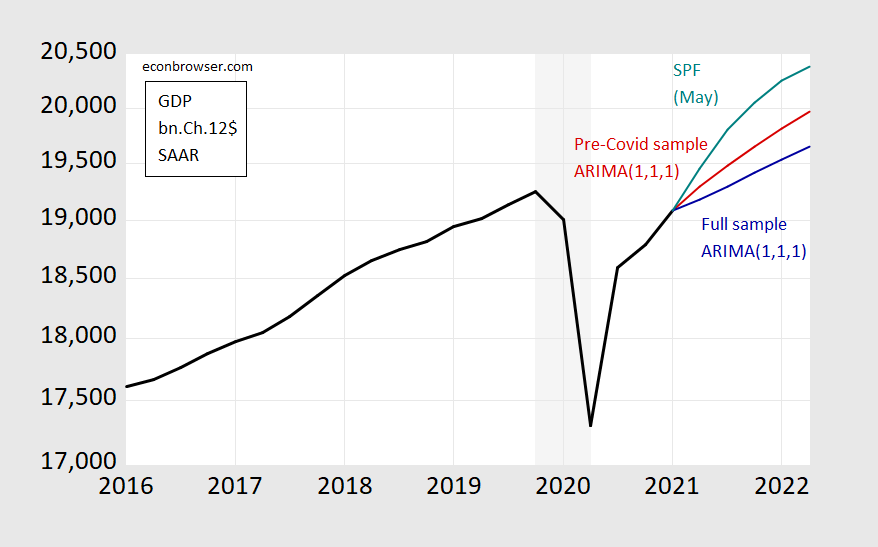
Figure 1: GDP as reported (black), median forecast from Survey of Professional Forecasters (teal), ARIMA(1,1,1) forecast using data 1986-2019Q4 (red), ARIMA(1,1,1) forecast using data 1986-2021Q1 (teal), all in billions of Ch.2012$ SAAR. Light gray shading denotes NBER recession dates assuming trough is at 2020Q2. Source: BEA, SPF, NBER, and author’s calculations.
One’s initial inclination is to use all the available information up to the most recent data (for 2021Q1) to estimate the relationships and to forecast. This leads to the blue line, where I use a simple time series model (ARIMA(1,1,1)), which traditionally has worked not altogether badly in a univariate context. Or, I could use the data available up to before the Covid-19 pandemic to estimate the relationships of interest. That leads to the red line.
Actual forecasters as surveyed by the Philadelphia Fed (teal line) project something different from both – but presumably they are doing something yet different from either. But in their case, they still have to confront the problems of what data to use (in addition to lagged output), what restrictions to impose on the model (Jim discusses these two issues in this post), what conditions to impose (will the infrastructure plan pass, will new Covid-19 variants spread and how far?), what additional variables to use (like big data, higher frequency data, etc.).
Paul Ho at the Richmond Fed summarizes some of the lessons learned in this period of forecasting in unprecedented times, in a much more sophisticated and comprehensive framework.
How Forecasters Adjusted to the New Environment
Faced with unique circumstances, forecasters had to acknowledge the difference without completely ignoring lessons from previous business cycles:
Should one view the COVID-19 pandemic as simply a period of high volatility?
Would economic variables comove differently than previous recessions?
Would the effects of the pandemic propagate and persist as other drivers of business cycles do?
These questions mattered for forecasts but did not have precise answers with the scarce amount of data available, especially in the early stages of the pandemic. How could forecasters tackle such questions as the pandemic unfolded, acknowledge the level of confidence in their answers and express how these questions influence their point forecasts and associated uncertainty?In a recent working paper, “Forecasting in the Absence of Precedent,” I discuss two broad approaches to dealing with the lack of precedent. First, forecasters used subjective judgment or prior knowledge — typically from economic theory — to adapt their models. Such model adjustments are most fruitful when their underlying assumptions are transparent and acknowledge the lack of certainty.
Alternatively, forecasters found new sources of information, typically by incorporating new data into forecasting models. For example, epidemiological and high-frequency data were of special interest during the pandemic. However, forecasters need to know how these new variables comove with variables of interest, which once more raises the question of model specification and the choice of assumptions. This Economic Brief focuses on several representative papers for each approach.
Note that forecasting is a separate (albeit related) enterprise from nowcasting. On the latter, in the context of the Covid-19 recession, see Econbrowser posts here and here. Some weekly indicators discussed here (OECD). Jim discussed the NY Fed and Atlanta Fed nowcast methodologies (pre-Covid-19) here.
It seems that a convicted rapist (Bill Cosby) gets a get out of jail card on a technicality:
https://www.nbcnews.com/news/us-news/bill-cosby-be-released-after-sexual-assault-conviction-overturned-pennsylvania-n1272748
And somehow the lead story is the total incompetence of the New York City Board of Electors. That’s news?
He sure had me fooled. My sister and I used to listen to his comedy records as kids, and had some of the biggest laughs and fun of our lives listening to those old LPs. He seemed to be pro-education, pro getting Blacks to get their butts into University and get a college degree. I’ve said before I consider myself a pretty good judge of character and pretty perceptive about people. Cosby is one who had me completely fooled. Sure, I knew he wasn’t a saint, I knew he had a gargantuan ego, and that he would endorse just about any product under the sun. Still his pounding the drum loudly for Blacks to get a college degree and quit bemoaning their lot in life when they couldn’t even get their butts into a classroom when public grade school education (as well as public libraries) was available, seemed to speak highly of the man. 100% reeled in by the con.
Cosby does benefit from high priced lawyers with no souls. His spokes person just now said this PA Supreme Court was a good day for blacks in America. What a disgusting comment. I’m sure his black female victims were not amused.
How many Blacks do you know who get off of multiple rape charges due to “prior agreements” with the DA/prosecutor or statute of limitations?? What this really shows is the “golden rule”. He who has the gold writes the rules. Which means if you are willing to pay the high dollar attorney, who also has given campaign contributions and other gifts to the judge overseeing the case, you’re going to get the sweetheart deal. So WHO should really be celebrating things like this??? Celebrity rapists and high-income rapists should break out the champagne……. You may have seen some on TV shows that are still currently being syndicated across this “great nation” of ours.
https://www.theguardian.com/us-news/2021/may/21/danny-masterson-that-70s-show-rape-trial
Which, since I know all MAGA members are “conservative Christians” they’ll be showing up to the trial to heckle this white male rapist.
I’m sure everyone remembers the annoying clown who represented Trump during the impeachment hearings – Bruce Castor. Well it seems he was the incompetent boob who gave Bill Cosby his get of jail card back in 2005!
https://www.newsweek.com/trump-impeachment-attorney-bruce-castor-cut-deal-that-overturned-bill-cosbys-conviction-1605737
One has to wonder how such an incompetent boob passed the bar exam. Then again – most lawyers I have met are not the sharpest pencils in the box except when it comes to get rich clients passes from responsibility.
I’m thinking there’s a heck of a lot of hurdles to jump here. The most recent being, how do you adjust GDP and/or inflation numbers for Delta variant’s effect in states with lower vaccination rates. You also still have entire nations with low vaccine rates or using poor quality vaccines, which has to effect world demand to a degree. I’m guessing these other nations’ lower demand has very little impact on USA domestic numbers or prices. Iran appears to have screwed up any short-term respite on oil prices by their toddler-ish militia actions against American troops. That’s too bad, because it would have benefited American consumers and I would think the Iranian economy.
How long does Biden wait to end sanctions on Iran, to signal attacking American troops is not something we will tolerate?? I think, at minimum, months, and probably a year plus, or Iran will keep having their militias commit these actions on American troops.
“I’m guessing these other nations’ lower demand has very little impact on USA domestic numbers or prices.”
Maybe Menzie has a good estimate of this but I would suggest weak aggregate demand in Europe has a significant negative impact on US exports.
A very interesting news story about labor shortages in UK.
https://www.cnn.com/2021/06/29/economy/global-worker-shortage-pandemic-brexit/index.html
Turns out that the rest of the world have labor shortage problems similar to those in US. But the rest of the world doesn’t have unemployment checks fluctuating dependent on political wills and short term bills. Nobody there ever got an extra stimulus unemployment bonus on top of regular payments. So it cannot be that people got lazy and stay at home because there was this extra generous federal pay on top of regular unemployment. The right wing narrative banging its head against the wall of reality again-again.
A big issue seems to be location mismatch. If a location has gotten the virus under control via things like vaccinations and social distancing, that location has a better chance of having people going back to work. A point missed by right wingers such as Bruce “no relationship to Robert” Hall who from the beginning advocates opening up and ignoring the scientists. As this story notes – this approach has backfired.
A couple of comments. First, most garden variety business cycles reflect changes in aggregate demand, either too much or too little. As a practical matter the usual set of macro tools (i.e., fiscal and monetary polices) are designed to manage the demand side of the economy. The Phillips curves are taken as fixed. I don’t think textbook macro is especially well equipped to handle the oddball case when we see exogenous shocks to both the demand and supply sides of the economy. Ultimately this gets to the different ways time series econometrics and conventional economics understand the term “equilibrium.” There’s a subtle but important difference between those two understandings.
Secondly, I think economists tended to focus too much on final demand (i.e., GDP) at the expense of bottlenecks across intermediate inputs. A little less attention to the BEA final demand GDP tables and a little more attention to the BEA I/O tables and Domar weights might have been a better way to manage gross output (i.e., final demand plus intermediate input demand).